To Save Work: Use the "Save World" button in the Features Panel. That saves text you have typed as well as the content of Scheme memory. Pixie Scheme III will reload the last saved world the next time you start the application. Pixie Scheme III will in any case automatically save whatever text is in its window whenever you leave the application, and restore it when you return, but you may lose things you have put in Scheme main memory if you do not use the "Save World" button as well.
Use a Separate Text Editor: Pixie Scheme III is best used with a separate application to prepare, edit and save Scheme programs. Pixie Scheme III's main window has simple, standard-iPad text-editing capability built in, but for anything more than a few lines of code, I recommend that you use whatever editing application you like, and cut and paste between it and Pixie Scheme III as necessary.
Introduction
Pixie Scheme III Startup Actions
Saving Your Work Between Sessions
Restoring Pixie Scheme III to Original Settings
Interacting with Pixie Scheme III
The Pixie Scheme III Window
How To Get Pixie Scheme III To Do Something
Using A Hardware Keyboard
No Tabs Allowed
The Dialog Panel
Buttons
Information Displays
Parenthesis Matching
Pretty-Printing
Pop-Up Panels
The Features Panel
The Help Panel
Another View of Interacting with Pixie Scheme III
Error Handling
Controlling Pixie Scheme III
The Garbage Collectors
Suggestions for Using Pixie Scheme III
Differences from R5 Scheme
Run-Time Text Input
R5 Section 1
R5 Section 2
R5 Section 3
R5 Section 4
R5 Section 5
R5 Section 6
Internal Representations of Numbers
Exactness -- Complex Numbers
Exactness -- "string->number" and "number->string"
#\tab and #\return
Slashification
R5 Section 7
Optional Features Omitted
Enhancements
Applicative Programming
Class System
Class System Procedure
Important Notes
A Simple Class Example -- Right Triangles
Creating and Using Methods
Inheritance
Inheritance -- A Familiar Example
Class Variables
Methods and Procedures as Variables
Class Summary
Compiler
Debugger
Lambda Expression "Names"
Forgettable Objects
Forgettable Object Content
Forgetting Behavior
Programming Interface to Forgettable Objects
Some Uses of Forgettable Objects
Logic Programming
Non-Printing Objects
Procedures and Forms
Bit Operations
Continued Fractions
Evaluation
Files and Directories
Infinities and Nans
Inspecting Scheme Objects
Long Ratnums and Continued Fractions
Macros -- An Alternate Implementation
Miscellaneous Predicates
Miscellaneous Procedures
Multiple-Values Objects and Operations
Numeric Formatting
Permanence
Print Length and Depth
Random Numbers
Sorting and Merging
State Flags
Storage Management
System Information
Top-Level Control
Sense Lights
Top-Level Loop Variables
Bugs, Flaws, Limitations, and Dealing with Them
Known Bugs and Flaws
Limitations
Common Problems and Solutions
Elementary Debugging
Timeline
What's New
What Used to be New
What Might be New in the Future
Miscellaneous Information
Numbers Revisited
Scheme References
Lisp References
Other References
Whimsy
On Dialectic and History
Excuses
Thanks To

Welcome to the help file for Pixie Scheme III, an implementation of the Scheme programming language for the Apple iPad™. Pixie Scheme III was written by me, Jay Reynolds Freeman. By all means EMail me about it if you wish.
Pixie Scheme III is an implementation of the "R5" dialect of Scheme (major Revision 5 of Scheme), that is missing several features.
Here are two other ways to explain what Pixie Scheme III is:
In contrast with Wraith Scheme, Pixie Scheme III has no file-system access, no support for parallel processing, no foreign-function interface, no interrupt mechanism, and only minimal user-controlled means to save and restore worlds: Those features are also rather beyond the intent and scope of the iPad.
This document is not a complete Scheme language description or programming manual. For a complete and authoritative manual, I strongly recommend that you obtain and peruse a copy of the 1998 Revised5 Report on the Algorithmic Language Scheme, edited by Richard Kelsey, William Clinger and Jonathan Rees. That report is available on several Internet sites, such as http://www.schemers.org.
You might also consider reading some of the Scheme References and Lisp References listed later herein.
All of Pixie Scheme III's procedures and special forms are described in detail, with examples and discussion, in the Pixie Scheme III Dictionary, which accompanies Pixie Scheme III. You can find it by using the Pixie Scheme III Help Panel.
The original Pixie Scheme was named after one of my cats -- "Pixie". If you don't think that naming a computer program after a cat makes sense, remember that it ran on a computer named after a raincoat.
On startup, Pixie Scheme III
Pixie Scheme III will automatically save all text in its window, as well as other details of your environment, whenever you leave the application, and will restore them when you return, but it cannot save information that you have put in Scheme main memory -- function definitions, data, and the like -- unless you give it a hand. You have to push a button -- the "Save World" button in the Pixie Scheme III Features Panel -- to make it happen. (Users of hardware keyboards may press "option-s" instead.)
I suggest that the way to use this mechanism is to get in the habit of saving frequently: Any time you are staring at the screen, wondering what to do next, let your fingers find the "Save World" button and press it. Furthermore, even though Pixie Scheme III will save the text in the main window when you leave the app, I recommend that you get in the habit of making a copy of the text in the main window occasionally, and pasting it somewhere else, in another application, for safekeeping. Don't think of the Pixie Scheme III window as a full-fledged program editor; its main purpose is to make it easy for you to get text into and out of Pixie Scheme III by cut-and-paste.
You don't need to know how the "Save World" mechanism works in order to use it -- just try it and see -- but if you are curious about what is going on, read on.
Pixie Scheme III is able to write a special kind of file, called a "world file", into the area of iPad memory that is reserved for its use. That file contains the entire content of Pixie Scheme III's main Scheme memory at the time -- all your Scheme definitions and Scheme data are in it. The world file also contains a lot of other information about what you were doing, including all the text that was in the main window, the font size in use, and a handful of other things about how you had Pixie Scheme III set up and what you were doing with it.
Every saved world overwrites the previous one. Thus the act of saving a world creates an up-to-date version of your Scheme "world" -- environment and data -- that will persist, even when you are not running Pixie Scheme III. Every time you start Pixie Scheme III, it looks in its reserved memory area for a saved world file. If it finds one, it loads it -- thereby restoring your Scheme procedures and data -- and also uses the additional information to re-create your working environment, so you can pick up from where you left off. If it cannot find a world file of yours, Pixie Scheme III will just load one of its own, that is stored in the application itself. (The only reason it might not find a world file of your own would be if you had never yet saved a world file, or if you had deliberately decided to restart the application in its original condition, as described immediately below.)
Pixie Scheme III's mechanism for saving only the text from the window works just like "Save World", but it is fast enough that I can make it happen automatically and reliably.
If for any reason you should become dissatisfied with the worlds you have been saving, you might consider using the "Reload Original Scheme World" button, that appears when you press the "Features" button at the lower left corner of the application. It will cause Pixie Scheme III to load the original world file -- which does not contain your personal saved Scheme data! When you use this button, Pixie Scheme III will not override any of the other settings and information in the environment you are using: For example, the font size will remain as you last set it. Furthermore, no text will be removed from the main window.
When you have reloaded the original world file, there may still be a saved world file around, that you had previously created by pressing the "Save World" button in the Pixie Scheme III Features Panel. Pixie Scheme III will try to start up using that saved world the next time you restart it. If you do not wish to use the saved world again, press the "Save World" button sometime after you have reloaded the original world, and before you next quit the application. That will overwrite the old saved world file with a new one.
To restore Pixie Scheme III to the way it was when you originally obtained it, use iTunes™: Connect your iPad to the computer you use to back up and maintain your iPad. Open iTunes and go to the iTunes window for your iPad, and press the "Apps" button at the top of that window. Uncheck Pixie Scheme III from the list of installed apps at the left side of that window, and then press the "Sync" button at lower right. After the sync has completed, recheck Pixie Scheme III in the list of installed apps, and press the "Sync" button again. The first sync will remove Pixie Scheme III and all its data -- including any saved world that you may have created -- from your iPad. The second sync will reinstall Pixie Scheme, which will use its own internal saved world the next time you launch it. You may then save new worlds to suit yourself.
I must note in passing that Apple updates iTunes frequently, so it is possible that small details of the layout and organization of the iTunes window for the iPad will have changed between the time I wrote these instructions and the time you read them. Notwithstanding, I expect that the general procedure of removing Pixie Scheme III from your iPad and then reinstalling it will still work, and that it will be accomplished by means very similar to what I have just described.
While you are reading this section, remember that there is also a section called Common Problems and Solutions.
The main part of the Pixie Scheme III Window is where you do almost everything with the Pixie Scheme III program -- things like entering Scheme source code, running it, and looking at the results. In addition to the usual iPad interface stuff, however, Pixie Scheme III provides a handful of buttons and a couple of status indicators. They allow you to do things to the Pixie Scheme III program -- things like setting options and taking control of Scheme programs that are misbehaving. They also allow you to keep track of what Pixie Scheme III is doing, and to access the program's internal help files and other documentation.
Note that Pixie Scheme III requires ASCII characters for everything it does. (ASCII characters are pretty much the letters of the English alphabet and the standard punctuation marks -- what you get from the keyboard of an old-fashioned typewriter.)
Technical Note: The requirement to use ASCII characters stems from the R5 report, which uses the ASCII character set to define what constitutes a "letter". It might be possible to interpret the R5 report as allowing non-ASCII characters in strings, and it would certainly have been possible to create a Scheme implementation that allowed all the fancy characters that the iPad can create. I chose to restrict the character set to ASCII to facilitate creating Scheme programs which can easily be adapted to run on other implementations of Scheme, that might not allow fancy characters.
Let's discuss the window and buttons in more detail.
The Pixie Scheme III window contains a large work area for text -- think of it as a blackboard or a slate where both you and the Pixie Scheme III program can write things. It also contains several buttons, pop-up panels, and information displays.
How To Get Pixie Scheme III To Do Something:
The Pixie Scheme III Main Window, at reduced size.
The idea is to type Scheme expressions into the Pixie Scheme III main window and evaluate them, whereupon Pixie Scheme III will type out the results in the main window, for you to look at. The next few paragraphs describe how to do that on a plain iPad. If you are using an add-on keyboard, there are some additional ways to do things that are described in the next section.
To evaluate a typed expression, select it in any of the usual ways (and there is one unusual one -- we will get to that in the next paragraph); then use a button which will appear at the top right corner of the main window, labeled "Evaluate": Press it to tell Pixie Scheme III to evaluate the selected expression.
Most of the time, when you are typing something into the main window, you are intending to select and evaluate what you have typed. Pixie Scheme III can help: The application remembers where you started your most recent batch of typing, and is prepared to select what you have typed at the push of a button. In more detail, it works like this. In the image above, note that the user has not typed any text yet, and that the button at the top right of the main window is invisible. In the image just below, the user has typed "(+ 2 2)", and now the top right button has appeared, with its label reading "Select That?".
Note that the matching parentheses of the typed expression are highlighted in green. Pixie Scheme III highlights matching parentheses this way whenever it finds them, but it ignores parentheses in strings (that is, between double-quotes) and in comments (that is, to the right of a semicolon). If you type a parenthesis for which there is no match, Pixie Scheme III will highlight it in a different color.
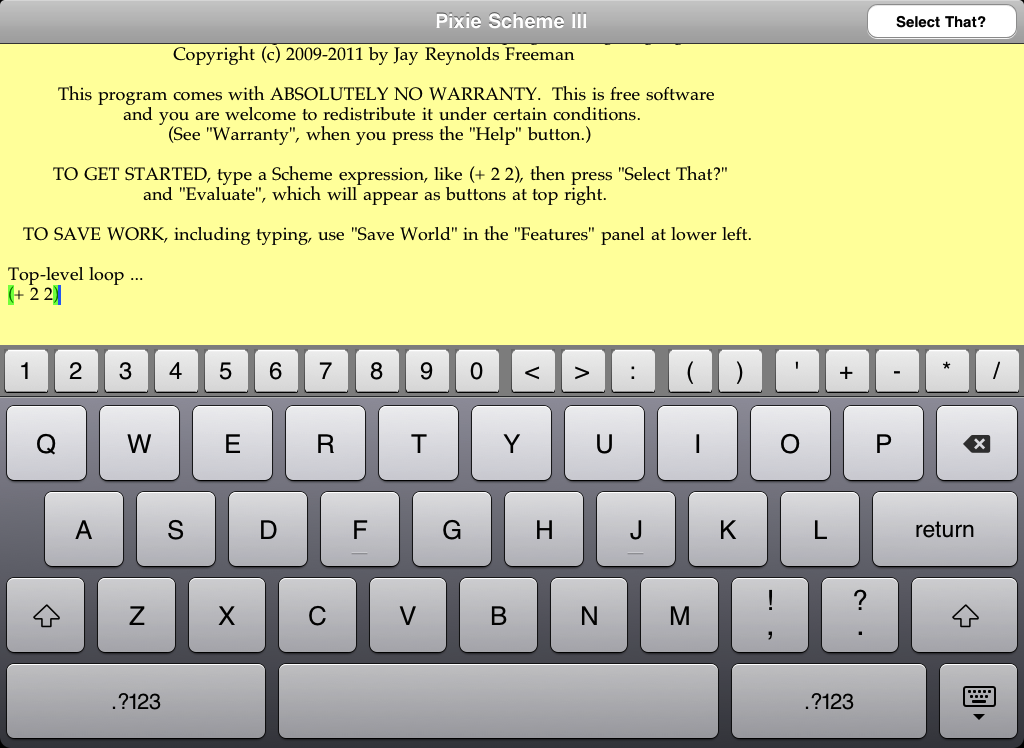
The Pixie Scheme III Main Window, with typed text, at reduced size.
In the next image, the user has pressed the "Select That?" button, the expression "(+ 2 2)" has been selected, and the top right button has changed its label, to "Evaluate".
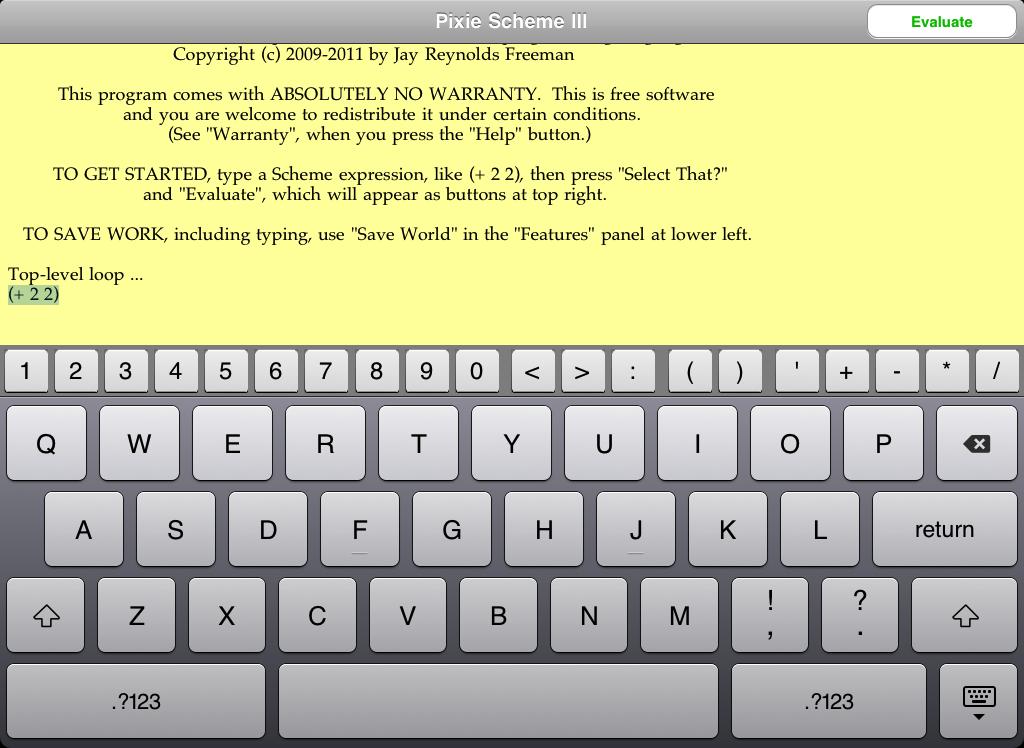
The Pixie Scheme III Main Window, with selected text, at reduced size.
When the user presses the "Evaluate" button, Pixie Scheme III evaluates the text selected, and prints out whatever may result, in this case the number "4". The last step would have happened the same way if you had selected the text by touching the screen and dragging the ends of the selection bar.

The Pixie Scheme III Main Window, showing an evaluation, at reduced size.
The flow of interaction with Pixie Scheme III this way should be very natural: You type an expression to evaluate, press the "Select That?" button to make sure what you are about to evaluate is what you think it is, then press the same button -- now labeled "Evaluate" -- again, to pass the expression to Pixie Scheme III.
The iPad's "cut-and-paste" mechanism is very useful for entering Scheme expressions: Pixie Scheme III will notice when you have pasted some text, and will enable the top right button as "Select That?", to make it easy for you to evaluate what you have put in.
By the way, I expect you noticed that Pixie Scheme III's "glass keyboard" has an enhancement: There is an extra row of smaller keys at the top. That row contains a selection of the most-used keys that you would have to shift to get if you were using the unenhanced glass keyboard. They work like the regular keys. They are even set up to make the same "click" sound that the regular keys do, provided you have enabled "Keyboard Clicks" in the first place. (To find that preference, go to the "Settings" app of your iPad, press the "General" tab and then press the "Sounds" button.)
There is one more thing to note about the extra keys: They are a little small. For that reason, I decided not to shrink the extra keys when you rotate your iPad to portrait orientation. Instead, the extra keys all stay the same size, but fewer of them are shown. There are twenty extra keys in landscape orientation, but only fifteen in portrait orientation.
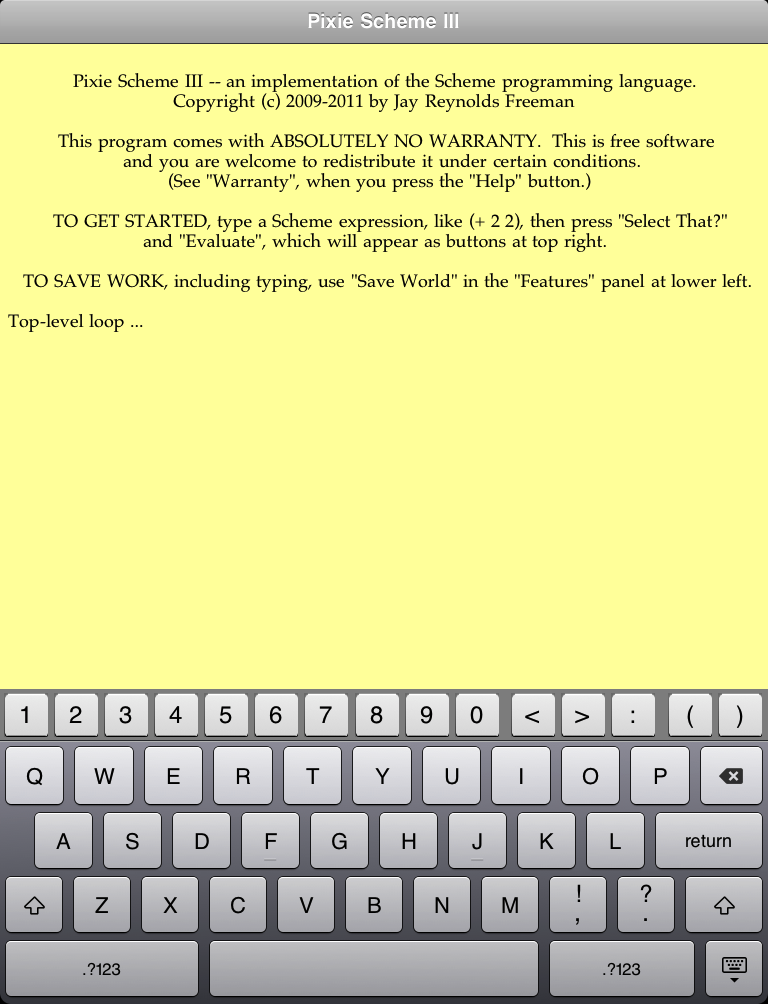
The Pixie Scheme III Main Window in portrait orientation.
The image above is at the same overall scale as the previous pictures that showed the keyboard in landscape orientation; that is, the dimensions of the whole screen are the same. As you can see, the regular keyboard keys are considerably smaller -- that's the way the iPad works. The extra keys are the same size they were in landscape orientation, but fewer of them are shown. I hope I have made a good tradeoff between having enough extra keys so that you don't have to shift too often, and having them too small to use.
If you are using a hardware keyboard with your iPad, there are a couple of shortcuts that use the "option" key, to help with common commands. (I would have liked to use the command key rather than the option key for keyboard shortcuts, but there seemed to be no way for an iPad app to tell that the command key has been pressed.)
When there are matched parentheses displayed, then pressing that same key, "option-&rsquo", will select all text between and including the parentheses. That will happen even if one of the parentheses is scrolled off the top or bottom of the window.
Things may become confused if you switch your hardware keyboard on and off, or if it stops working, while you are in the middle of using Pixie Scheme III. Pixie Scheme III may not be able to figure out for sure whether a hardware keyboard is there until you have done a few keyboard operations. To get things back to normal, try rotating the iPad a few times, so that the orientation of the screen switches back and forth between landscape and portrait. If the hardware keyboard is not on, you might also try moving the glass keyboard up and down by the usual taps and key presses. As a last resort, press the "Home" button to leave Pixie Scheme III for a moment, then start it back up again. Caution: You might want to save your work -- that is, save a world -- before you do.
It may seem a bit odd to use "real" characters, like "option-&rsquo" and "option-s", for keyboard shortcuts. That is possible because the R5 Scheme specification allows only ASCII characters for input to Scheme itself. Thus Pixie Scheme III is free to intercept non-ASCII characters and treat them as keyboard shortcuts. When you type "option-&rsquo", what gets sent to Pixie Scheme III -- and intercepted -- is actually the non-ASCII character 'æ', and when you type "option-s", what gets sent is 'ß'.
Pixie Scheme III will not allow "tab" characters as inputs. If you type a tab, or paste in some text containing tabs, Pixie Scheme III will silently convert each tab to a single blank space.
If you are looking at a standard iPad, whose keyboard has no "tab" key in the first place, you may be wondering how you could possibly get a tab into Pixie Scheme III. The answer is, that some of the accessory hardware keyboards available for the iPad do have "tab" keys, or that you may have pasted in some text that was originally created in an application where tabs were available.
Incidentally, if you wish to use tabs in the output of Pixie Scheme III, there are ways to do that. See the sections on #\tab and #\return and on slashification.

Pixie Scheme III's Dialog Panel.
The Pixie Scheme III Dialog Panel occasionally drops down from the top of the Pixie Scheme III window, when the program needs some kind of text input from the user.
You don't actually need to type a response: You may also use cut-and-paste, as long as your response is just one line long.
In a typical dialog, Pixie Scheme III might ask you for the content of a string.
In the paragraphs above, I have already mentioned the button at the
top right of the main window. It appears, with label "Select
That?", when Pixie Scheme III knows about a range of text in the main
window that you might wish to select. It appears, with label
"Evaluate", when a selected range of text is marked in the main window. At other
times, the button is not visible.
There is also a button at the top left of the main window, labeled "Reset Scheme".
It appears only when Pixie Scheme III is evaluating something. You may
press it then to make evaluation stop. That would be useful, for
example, if the code that was running was in an infinite loop.
The Reset Scheme button, at top left of the Pixie Scheme III Main Window.
If for some reason Pixie Scheme III is running very slowly while it is
processing text to be evaluated, then you may temporarily see this
same button with the title "Forget Typing". Pressing the button at
that time will cause Pixie Scheme III to stop processing that text.
The Pixie Scheme III Main Window contains several items that display information
to the user.
Pixie Scheme III's memory level indicator.
The labels for the memory level indicator are only visible when your iPad
is in landscape orientation. There isn't enough room for them in portrait
orientation.
The total amount of memory available is 40 MByte, and 4 MByte are reserved for the
use of Pixie Scheme III's
generational garbage collector.
If main Scheme memory fills up, and no memory can be freed by garbage
collection, you will have to restart Pixie Scheme III. In extreme
cases, you may even have to
restore Pixie Scheme III to original settings.
The garbage
collector runs automatically, but you can force a garbage collection
at any time by evaluating "(e::full-gc)".
Pixie Scheme III's garbage-collection and evaluation lights.
The garbage-collection light is labeled "GC", and it glows red when
garbage is being collected. The evaluation light is labeled "Eval", and
it glows magenta when Pixie Scheme III is evaluating something -- loosely,
when Pixie Scheme III is "busy".
Pixie Scheme III's sense lights, glowing various colors.
The sense lights are controlled by the user; the procedures to do so are
described in a Sense Lights section below.
The preceding image is only to show where they are.
Pixie Scheme III attempts to show matching parentheses as you type and
select text, by highlighting them in color. When the cursor is just to
the right of a parenthesis that has a match, both parentheses will
be highlighted in green. When the cursor is just to the right of a
left parenthesis that does not have a match, that parenthesis will be
highlighted in orange. When the cursor is just to the right of a
right parenthesis that does not have a match, that parenthesis will be
highlighted in red.
Parenthesis matching ignores parentheses that are in comments, in
strings, or in the form of Scheme characters. That is, Pixie Scheme
III's parenthesis-matching algorithm will ignore the following
parentheses:
Strictly speaking, the parenthesis matcher can only hope to work on
text that is syntactically correct Scheme code -- something that
a Scheme interpreter can understand and evaluate. If you enter some incorrect
Scheme code -- something that will cause an error when Pixie Scheme
III tries to parse it -- and that code contains parentheses, the
parenthesis matcher may become confused until you have fixed the
problem: It is not smart enough to guess what you meant to do.
If for any reason the parenthesis matcher becomes confused and
seems inclined to stay that way, just
save a world, put the
Pixie Scheme III application in background by pressing the "Home"
button, and then return to it. Pixie Scheme III will reanalyze all
the parentheses when it returns from background. If the problem
persists, you might also want to send a bug report to
Jay_Reynolds_Freeman@mac.com.
You don't actually
need to save a world if you don't mind accepting some chance of losing recent work,
in case iOS decides to shut down Pixie Scheme III while it is in the background.
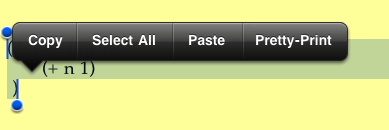
Pixie Scheme III has simple pretty-printing available. When you
select some text and tap so that the edit menu comes up, if the
selected text is a parenthesized expression, the edit menu will have
an extra item on it, "Pretty-Print". Tap that item, and Pixie Scheme
III will pretty-print the selected expression; that is, it will reformat
the expression using indentation to show how deeply parentheses are nested.
The next three pictures show how it works.
A parenthesized expression, ready to tap and bring up the edit menu.
The edit menu has a new item, "Pretty-Print", at the right end.
The resulting pretty-printed expression.
The pretty-print is very simple: The extra leading white space for
each line is composed of exactly twice as many blank-space characters as
there are unbalanced left parentheses between the start of the
expression and the start of the line. There are much fancier
algorithms, but different programmers like different pretty-print
styles, and there is no pleasing everyone. Yet the real purpose of
pretty-printing is not to make code look good, but to make it easy for
programmers to see the structure of what they have written, and I
believe this minimal routine will do the job.
Pixie Scheme III's complete bottom bar, at reduced size.
Pixie Scheme III has two pop-up panels -- Apple sometimes calls these
"popovers" -- that provide access to special features and information.
They pop up when you press the "Features" button or the "Help" button,
which are located respectively at the left and right ends of the bar
at the bottom of the Pixie Scheme III window.
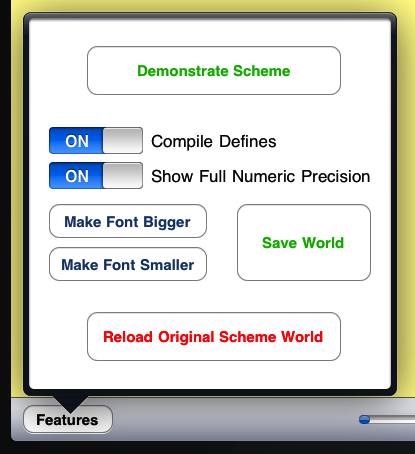
The Features Panel.
The Features Panel pops up when you press the "Features" button, at
the lower left corner of the Pixie Scheme III main window.
This switch toggles between the "number->string" mechanism and a
simpler output format, in which floating-point numbers are displayed
with at most seven decimal digits, and explicit exact and inexact
prefixes ("#e" and "#i") are not used. This toggling applies only to
the procedures "display" and "write", and to output at top level in
the Pixie Scheme III window. The strings returned by "number->string"
itself remain unchanged. The internal representations of numbers
remain unchanged.
I put in this feature because some people use a Scheme interpreter as
a very fancy calculator, and they might get tired of looking at
numbers in unnecessarily long formats. Furthermore, the use of the
full precision of "number->string" sometimes produces counterintuitive
least-significant digits. Thus if you are using the full precision
and type in
Pixie Scheme III will print
which is correct in terms of "number->string" -- that is, that
number is the best approximation to (/ 1 3) that the system can provide --
but that final "1" might look suspicious if you were expecting
"3"s to infinity, and beyond.
Whenever you start Pixie Scheme III, it looks for a saved world
file, and loads it if it finds one. Thus you start off with a
copy of the work you had done at the time you last saved a world.
If there is no saved world file at that time, Pixie Scheme III
will start up using a world file stored within the program itself.
It may take as long as 30 seconds to save a world file, if Pixie
Scheme III's memory is nearly full at the time you try to do so.
It seemed like a bad idea for me to provide an automatic "Save World"
mechanism that worked some of the time but occasionally failed without
warning. You might get used to it doing its job, and then you would be
justifiably upset when it didn't. Therefore, Pixie Scheme III will never
attempt to save a world automatically; you must do it yourself.
Of course, just because you put the app in the background doesn't
make it certain that iOS is going to shut it down. When you next bring
Pixie Scheme III into the foreground, you may find it still
running, with everything as it was before. Just don't count on it!
When you press this button, Pixie Scheme III will ask you to
confirm that you really meant to do so.
Pressing this button does not erase text from the main
window. You can still recover any Scheme source code that may
be present there by cut-and-paste, and you may of course recompile
or rerun it if you wish.
The Help Panel.
The Help Panel pops up when you press the "Help" button, at the
lower right corner of the Pixie Scheme III main window.
It provides access to some HTML files and text files that tell how
to use Pixie Scheme III, and provide other information.
There is another way to think about how you may interact with Pixie Scheme III:
There are four ways for Pixie Scheme III to provide information to you:
There are three ways for you to provide information to Pixie Scheme III:
When Pixie Scheme III encounters an error from which it can recover, its
general strategy is to print an error message -- I hope a useful one
-- in the Pixie Scheme III Window,
then abort whatever Scheme processing is going on and return control
to you at "top level" in the Pixie Scheme III window. For example,
suppose you tried to add using a Scheme object that is not a number.
You might type:
whereupon Pixie Scheme III would print
A similar error message, and a similar return to the "top level" of
control of Pixie Scheme III, would occur even if the problem
occurred deep in some elaborate Scheme procedure.
Pixie Scheme III may also encounter errors from which no recovery is
possible, in which case its general strategy is to open a special
panel to present an error message, and then exit. If you should ever see a
fatal error message whose cause is not obviously due to something
you understand and can control yourself, I would like to hear
about it: Send bug reports to
Jay_Reynolds_Freeman@mac.com.
(That Scheme command is one of the
Enhancements provided by Pixie Scheme III.)
This procedure causes an immediate exit: Pixie Scheme III
will not save any kind of data about your work, and will not save
the content of Scheme memory. The procedure provides a way to
run a Scheme program that can exit automatically when it is done.
It is also a guaranteed way to shut down the app completely, if for some reason
you really want it to quit at once, rather than just to go into the
background.
This way to quit only works if the Pixie Scheme III window is accepting
commands, which it won't be, for example, if a long Scheme procedure
is running; you might have to use the "Reset Scheme" button -- described
a few paragraphs above -- first.
Reclaiming memory that is no longer in use is an important part of any
computer application, and Lisp systems of all kinds have long been
equipped with "garbage collectors" to perform that task. Pixie Scheme
III has two garbage collectors, so it is important to tell you a little
about what they are and how they work together.
Pixie Scheme III has both a full garbage collector and
a generational garbage collector. These two systems are not completely
independent, as we shall soon see. The reason for having two systems is that the full garbage
collector sometimes takes an objectionable amount of time to do its job: Pixie Scheme III would
just sit there, with the red "GC" light turned on, for long enough to bother you.
The generational garbage collector addresses this problem by doing
frequent garbage-collection operations that each only collect a little
bit of garbage. Since the amount of garbage collected per collection
is small, the operations are fast, and Pixie Scheme III is more
responsive. On the other hand, the combined time to set up and do
many small collections turns out to be more than the time required for
one full collection that collects the same amount of garbage, so
Pixie Scheme III's overall speed is lower when the generational garbage
collector is running, than when it is not.
Furthermore, the generational garbage collector is not as efficient as
the full one: Some garbage sneaks through it without being collected.
Therefore, even when the generational garbage collector is running, Pixie
Scheme III has to do a full garbage collection occasionally.
So both garbage-collection systems have pros and cons.
Notwithstanding, for simplicity, I decided to make Pixie Scheme III
always use the generational garbage collector. I mention the full
garbage collector here only because the generational one uses it from
time to time, and because you yourself may request a full garbage
collection by evaluating "(e::full-gc)".
This section includes some hints based on my own personal experience in using Pixie Scheme III.
What's here is in no sense required practice, or even best practice, it is just a list of
miscellaneous tips that have made my own life easier when I myself use Pixie Scheme III to
develop and run programs.
Some of these matters are complicated, in the sense that you may need more than just
a little knowledge of programming and the Unix / iOS operating system in order
to understand what I am talking about. If that happens, I apologize, and it won't
do any harm to ignore that suggestion entirely.
Herein I describe how Pixie Scheme III differs from "R5" Scheme by
going through the
Revised5 Report on the Algorithmic Language Scheme,
section by section, and listing differences between Pixie Scheme III and
that standard. It is my intention that any essential or non-essential
feature of Scheme that is mentioned in the R5 report, is either provided
as described in the R5 report, or mentioned here with an indication of how Pixie
Scheme III differs from the R5 report.
One major difference is that Pixie Scheme III provides numerous
enhancements and special features, in great part in the form of extra
built-in procedures and constants whose identifiers generally begin
with "e::" or "c::". I mention some of these features in passing in
this section, keeping the descriptions brief for clarity of
presentation. I have described them in more detail in a separate
Enhancements section.
I have summarized the R5 features that Pixie Scheme III lacks,
in the Optional Features Omitted section.
Each missing feature is also mentioned separately in the
discussion of the appropriate section of the R5 report, below.
Note that all of Pixie Scheme III's procedures and special forms are described in detail,
with examples and discussion, in the
Pixie Scheme III Dictionary,
which accompanies Pixie Scheme III and may be reached
via the Pixie Scheme III Help Panel.
Some procedures that take string arguments will ask you to type in the
string to be used when they are called without the argument that
normally provides that information. These procedures use the Pixie
Scheme III dialog panel, that drops down from the top of the Pixie Scheme
III main window.
For example, in straight "R5" Scheme,
is not a legal expression -- "make-string" requires an argument.
In Pixie Scheme III, however,
will display the dialog panel with a place for you
to type in the intended content of the string. The full
list of standard Scheme procedures that are modified to work this
way in Pixie Scheme III is:
Several non-standard procedures, described in the "Enhancements" section, also work this way.
1.3.1:
Unless otherwise stated, Pixie Scheme III supports all features of
Scheme, including optional ones, that are described in the R5
report.
1.3.2:
Pixie Scheme III attempts to print sensible error messages for errors
indicated in the R5 report, even when the R5 report does not require
that an error be signaled. In general, Pixie Scheme III will print an
error message and then return control to the top level of the Scheme
interpreter. If the error occurred within a user-defined function,
Pixie Scheme III may provide some rudimentary debugging information, such
as the names of functions on the call stack when the error occurred.
Some errors are fatal: For them, Pixie Scheme III will in general display
an error message in a special panel, and then exit.
Where R5 states that the value of an expression is unspecified, Pixie
Scheme III generally returns #t.
1.3.5:
Pixie Scheme III provides numerous functions and variables as enhancements to R5 Scheme, and distinguishes
them by naming conventions. In particular, Pixie Scheme III uses symbols
which begin with the characters "e::" for enhancements that in my
opinion will probably be of broad interest to users, and "c::" for
more specialized enhancements that will probably be less generally
useful. For example,
names a function of no arguments which may be called to exit from
Pixie Scheme III.
The syntax of these naming conventions was inspired by various
"package" and "namespace" mechanisms used in other Lisp
implementations, but there is no such mechanism in Pixie Scheme III;
that is, "e::" and "c::" are just some of the characters in the identifier.
2.1:
Identifiers in Pixie Scheme III are independent of alphabetic case. Thus
for example, Pixie Scheme III considers "define", "DEFINE", "Define", and
"dEfiNE" all to be the same identifier.
Pixie Scheme III prints identifiers with lower-case letters. Thus
returns
There is a well-known "gotcha" in the specification of identifiers
in the R5 report: The language of that report allows identifiers
to begin with the character '@', but the use of such identifiers
creates syntactic confusion with the symbol ",@" that Scheme uses
as shorthand for "unquote-splicing". Thus, consider the Scheme
expression
Is that to be understood as
or as
Given the possibility that identifiers begin with '@', Scheme has
no way to distinguish between the two interpretations.
Therefore, in Pixie Scheme III, identifiers may not begin with '@':
The character '@' may occur within an identifier only in positions other than
the first letter.
All identifiers that are syntactic keywords, all identifiers
associated with procedures defined in R5, and all identifiers for
enhancements provided by Pixie Scheme III, are bound to the code that
executes those procedures, in a manner difficult to change. You must
undo these "permanent" bindings in order to perform such interesting
operations as "(set! cons ...)". Pixie Scheme III uses an internal flag
for each binding to indicate whether it is "permanent", and provides
the functions "e::permanent?", "e::set-permanent!" and "e::clear-permanent!"
-- each taking an identifier as argument -- for your own use, at your
own risk. For example
returns #t.
Pixie Scheme III does not uniformly allow syntactic keywords to be used as
variables, though the mechanisms used to implement hygienic macros will
sometimes allow you to get away with doing so.
2.2:
Pixie Scheme III recognizes tabs, carriage returns, newlines and
blank spaces, as whitespace.
No comments.
4.3:
In addition to the hygienic macro implementation described in
this section of the R5 report, Pixie Scheme III has an additional,
low-level macro implementation, described in
Macros --
An Alternate Implementation.
5.2:
Pixie Scheme III will not always report an error if internal definitions
are used incorrectly within what the R5 report calls a "<body>"; that is, at
locations in the <body> other than at the beginning. Internal definitions at
locations within a <body> other than at the beginning bind and
assign within the top-level environment, not locally. Internal definitions
at the beginning of a <body> act within the local environment of that <body>.
That is not to say that you should put definitions in such places.
In Pixie Scheme III, "define" recursively searches the expression being
bound or assigned for macro "calls", and expands any that it finds.
Pixie Scheme III allows optional automatic compilation of top-level
defines, by means of the "compile defines" item in the
Features Panel.
Any such compilation takes
place after macro expansion, and only for procedures defined using the
procedure-defining syntax that involves parentheses around the
name and formal parameters.
Pixie Scheme III does not support irrational numbers.
Pixie Scheme III's support for rational numbers in which the numerator
and denominator are stored as separate values is limited to numbers
in which both the numerator and the denominator are within the
range of 64-bit signed integers. In other circumstances, Pixie
Scheme III generally divides the numerator by the denominator and
remembers only the quotient.
Pixie Scheme III's rational numbers in which the numerator and
denominator are stored separately are anticontagious in
the sense that Pixie Scheme III arithmetic and mathematical operations
will not attempt to produce such numbers as results
unless all of their inputs are of that kind. (Those
operations of course may not even be able to produce such results
at all, if the mathematically correct results would require the use of integers
outside the range of 64-bit signed integers.)
Furthermore, Pixie Scheme III's transcendental functions will not attempt
to produce such results, "sqrt" will not attempt to do so unless its input
is itself a perfect square of either an integer or a fraction, and "expt"
will only attempt to do so for a power that is a nonnegative integer.
You may create rational numbers in which the numerator and denominator
are stored separately as literal constants, by using the input form
e.g.
or you may use the procedure "e::make-long-ratnum", which is one of
Pixie Scheme III's enhancements for dealing
with such numbers.
Pixie Scheme III supports four internal representations for numbers:
64-bit signed fixnums (which I sometimes call "fixnums"), IEEE 64-bit
flonums (which I sometimes call "flonums"), and two long forms which I
call "long complexes" and "long ratnums". Long complexes are used for
complex numbers with nonzero imaginary part. A long complex contains
two numbers, each in one or the other of the 64-bit representations;
the two numbers are the real and imaginary parts of the complex
number. Long ratnums are used for rational numbers in which the
numerator and denominator are both remembered separately; the two
numbers are the numerator and the denominator.
A number stored in either of the 64-bit formats is necessarily either
an integer or a rational. Therefore, the procedures "rational?",
"real?" and "complex?" will always return #t when applied to any
number stored by Pixie Scheme III that has nonzero imaginary part. These
three procedures, as well as "integer?", will return #f when applied
to any Pixie Scheme III number that contains a IEEE floating-point
infinity or nan.
6.2.2:
There was a problem in the implementation of "eqv?" required by the R5
report, when dealing with complex numbers. I have resolved the
difficulty as later specified in the R6 report.
The problem was that the R5 report required two complex numbers to
be "eqv?" if both had the same numeric values for their real and
imaginary parts, and if both also had the same value of the exact bit.
Thus in particular:
because both 1+1.i and 1.+1i are inexact. The
idea of "eqv?", however, was to capture the notion that equivalent objects give
the same result when subject to arbitrary Scheme operations, and in
that context it was disturbing that
that is, that the real parts of two supposedly equivalent quantities
were not the same, one being exact and the other inexact. (The same
is true of the imaginary parts of a and b as well.)
The R6 report changed the rules for "eqv?" in such a way that
complex numbers are not "eqv?" if they have real or imaginary
parts of different exactness. Pixie Scheme III implements that
behavior. Furthermore, the R5 report defines "equal?" for numbers
in terms of "eqv?"; thus in Pixie Scheme III, complex numbers are not
"equal?" if they have real or imaginary parts of different exactness.
That is:
6.2.3:
Pixie Scheme III attempts to preserve maximum accuracy and precision when
doing arithmetic. Thus in general, operations yield a result with at
least as much precision as the most precise of their operands.
The IEEE floating-point standard provides representations to indicate
when floating-point overflow has taken place, and to indicate when an
operation cannot produce a numeric result. These representations are
called "infinities" and "nans". ("Nan" stands for "not a number".)
Pixie Scheme III handles these representations so as to facilitate
calculations: Procedures that both accept and return numeric values
generally accept infinities and nans without balking, and return
whatever value is appropriate. However, procedures which perform an
explicit or implicit ordering of numeric values report an error when
called with a nan as argument. Those procedures are:
Furthermore, the procedures
The type-checking procedures
return #f when called with either an infinity or a nan as an argument.
Infinities and nans are always inexact.
Pixie Scheme III has some procedures to tell whether Scheme objects
are infinities or nans.
These procedures are enhancements.
Pixie Scheme III prints all nans as "nan", and all infinities as "inf".
The printed representations of infinities make no distinction between
positive and negative infinities, though the internal representations
are in fact signed, and their signs can be determined by such
procedures as "positive?" and "negative?".
Pixie Scheme III will produce infinities or nans when it
detects an attempt to divide by zero.
6.2.4:
The syntax of Pixie Scheme III's numeric constants is insensitive to
alphabetic case. #E works as well as #e, #Xfeed is just as good
a hexadecimal representation of 65261 as is #xFeeD, 2.0E0 represents
the same number as 2.0e0, and so on.
Pixie Scheme III allows numeric constants to be written as fractions --
such as 22/7 -- but has no means to store numerator and denominator
separately; instead, it performs the division and returns the result.
Informally, Pixie Scheme III "reads fractions", but remembers only their
numeric value.
Pixie Scheme III will not override a user's use of an explicit exact
prefix ("#e") with a number if the number contains too many digits to
be stored exactly.
Pixie Scheme III will report an error when a string used to represent
a numeric constant contains both an explicit "exact" prefix ("#e")
and one or more sharps in places where digits might be expected.
Thus the text string
-- which might conceivably be intended as a number with value somewhere
near 1200 -- is not recognized as a number by Pixie Scheme III.
Pixie Scheme III will report an error when characters are used in the
written representation of a number that are inappropriate for the
implicit or explicit radix. Thus if you enter
or
Pixie Scheme III will report an error, whereas
will evaluate to
Pixie Scheme III supports four internal representations for numbers:
64-bit signed fixnums (which I sometimes call "fixnums"), IEEE 64-bit
flonums (which I sometimes call "flonums"), and two long forms which I
call "long complexes" and "long ratnums". Long complexes are used for
complex numbers with nonzero imaginary part. A long complex contains
two numbers, each in one or the other of the 64-bit representations;
the two numbers are the real and imaginary parts of the complex
number. Long ratnums are used for rational numbers in which the
numerator and denominator are both remembered separately; the two
numbers are the numerator and the denominator.
Pixie Scheme III generally uses 64-bit fixnums to store signed integers
from -9,223,372,036,854,775,807 through 9,223,372,036,854,775,807,
(that number is two to the sixty-third power, less one) and uses IEEE
64-bit flonums to store numbers outside that range. Notwithstanding,
it is possible that an integer in the range -9,007,199,254,740,991
through 9,007,199,254,740,991 (that number is two to the fifty-third
power, less one) will be stored as an IEEE 64-bit
flonum: That storage form has enough bits to store such
integers without loss of precision.
Pixie Scheme III generally observes "flonum contagion", in that when
at least one of the operands of a mathematical operation is an IEEE
64-bit flonum, the result will usually be an IEEE 64-bit flonum.
When converting from an external representation of a number to an
internal representation, Pixie Scheme III will take the presence of any
of the normal Scheme exponent markers -- "d", "e", "f", "l", and "s"
-- as reason to store the number in question as an IEEE 64-bit flonum.
6.2.5:
The procedures "=", "<", ">", "<=" and ">=" each take two or more
arguments. The procedure "=" returns #t if and only if its arguments
are all equal. The procedure "<" returns #t if and only if its
arguments form a sequence that is strictly increasing; that is, if and
only if each of its arguments is greater than its neighbor to the left
(if any) and less than its neighbor to the right (if any). The other
procedures have similar semantics.
The procedures "quotient", "remainder", "modulo", "gcd" and "lcm" are
implemented only for integer arguments whose absolute value is less
than 9,223,372,036,854,775,807. If they are called with integer
arguments that happen to be stored as flonums, not as fixnums, then
they will report an error if any such argument is outside the
range in which it can be stored as a flonum without loss of accuracy.
The error messages for out-of-range arguments will state that the
argument is of improper type, but will not specifically mention that
the problem is one of range. These messages may be confusing if you
have not noted the range limit just given.
Furthermore, if the algorithm for "lcm" requires a temporary value
outside this range, Pixie Scheme III will be unable to finish without loss
of precision, and will report an error.
"Gcd" and "lcm" return IEEE 64-bit flonums when one or more of their
arguments are IEEE 64-bit flonums.
6.2.6
Although "string->number" recognizes numbers written in fraction notation,
the best that Pixie Scheme III can do with them is store a single number whose
value is the numerator divided by the denominator. Thus "number->string"
will never print a number as a fraction.
If a complex number has a non-zero imaginary part, Pixie Scheme III will
store each of its real part and its imaginary part separately, as
separate, full-fledged Pixie Scheme III real numbers. The real and
imaginary parts each have their own separate exact bits, and thereby
is created some confusion about the exactness of the complex number
as a whole: How should Pixie Scheme III handle complex numbers whose
real and imaginary parts have differing exactnesses, and what exactness
should be reported for such a complex number considered as a whole?
The obvious solution of reporting a complex number as exact if, and
only if, its real and imaginary parts are both exact, does not work.
If that solution were implemented, then consider the two complex numbers
1+1.i and 1.+i: In the first, the real part is exact and the imaginary
part is inexact, and in the second, the exactnesses are reversed.
These two complex numbers would be numerically equal and would have
the same exactness, yet would not behave equivalently under standard
Scheme procedures: For example, "real-part" would
return different values for the two numbers, and so would
"imag-part".
To avoid this conundrum, Pixie Scheme III will not allow a complex number
to have real and imaginary parts with differing exactnesses. In that
context, in brief:
Let me summarize how Pixie Scheme III's implementations of string->number
and number->string deal with exactness. I believe that Pixie Scheme III
handles these matters correctly, but this section of the R5 report is
a bit obscure, and does allow implementors some leeway. The following
rules tell how the external representation of a number -- what you
type, and what Pixie Scheme III prints -- corresponds to the exactness of
Pixie Scheme III's internal representation of that number.
The idea is that numbers input to Pixie Scheme III are considered exact
unless some feature of the external representation -- typically one or
more embedded "#"s or an explicit inexact prefix ("#i") -- indicates
otherwise.
There is a complication with numbers that are expressed in base 10.
The problem is, that there are additional means of indicating
exactness available to external representations of those numbers:
Base 10 is the only base in which the external representations of
numbers are allowed to have decimal points or exponents. These act as
indicators of inexactness, but "weakly", in that their indications may
be overridden by explicit exact prefixes.
In a little more detail:
Thus, examples of numbers which both you and Pixie Scheme III should
consider inexact are:
And examples of numbers which both you and Pixie Scheme III should
consider exact are:
Thus, examples of numbers which both you and Pixie Scheme III should
consider inexact are:
And examples of numbers which both you and Pixie Scheme III should
consider exact are:
Thus, examples of numbers which both you and Pixie Scheme III should
consider inexact are:
And examples of numbers which both you and Pixie Scheme III should
consider exact are:
The reasoning as to why numbers such as these are not printed is that
(1) Pixie Scheme III uses the standard Scheme procedure "number->string"
to print numbers, and (2) R5 Scheme requires that procedure to print
base-10 inexact numbers with a decimal point, except for
infinities and nans, and (3) R5
Scheme requires that the presence of an exponent, without an explicit
exact prefix, be taken to mean that the number in question is inexact.
Yet even though Pixie Scheme III will not print these numbers as output,
it will recognize them when input, as respectively inexact 100 and
inexact -100, in base 10.
Exact prefixes and the like notwithstanding, Pixie Scheme III cannot
necessarily store a number that is mathematically identical to a given
external representation. For example, Pixie Scheme III stores #e1.3 as a
number that is certainly not 1.3, but that differs from it by a few
digits a long way to the right of the decimal point. Furthermore, if
you type in a long string of digits, with no decimal point or
exponent, Pixie Scheme III will interpret what you have typed as an
integer and will do the best it can to store it, but if you have typed
too many digits, the ones farthest to the right will have no effect on
the value stored. Thus if you type



Parenthesis Matching:
Technical Note: The reason for using orange for
unmatched left parentheses but red for unmatched right parentheses is
that when you are typing Scheme code, it is common to type the opening
'(' of an expression before you type the matching, closing ')'. In
that case, a mismatched '(' isn't really an error, it merely indicates
that you aren't done typing yet, so a highlighting color that
indicates caution -- orange -- seemed appropriate. On the other
hand, typing an unmatched ')' is usually an error, so a red highlight
appeared to be a better choice there.
"This left parenthesis --> ( <-- is in a string."
;; This right parenthesis --> ) <-- is in a comment.
(list #\( #\) ) ;; Those parentheses are how Scheme
;; represents the ASCII characters
;; '(' and ')'.
Pretty-Printing:
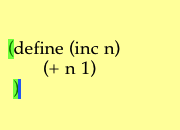
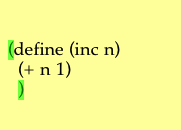
Pop-Up Panels:

Technical Note: With "full precision", Pixie Scheme III's
"display" and "write" behave like the Scheme function
"number->string": They show all the precision the internal
representation of the number has, and they make certain to print
something that will let you know whether the number printed is exact
or inexact.
(/ 1 3)
0.33333333333333331
Technical Note: When you put an iPad app into the
background, iOS may subsequently decide to shut it down
completely. When and if that happens, iOS will give the app
a little time to tidy itself up and arrange that the shutdown
goes smoothly, but the amount of time provided might be as little
as five seconds. Since Pixie Scheme III can take as much as
30 seconds to save a world file, it follows that Pixie Scheme
III cannot guarantee a successful world save
when you put it into background.

Another View of
Interacting with Pixie Scheme III:
Error Handling:
(+ 2 #t)
#<Built-in procedure "+"> applied to (2 #t):
-> #t
Expected a number for argument list item 1 (zero-based).
Problem: Marked argument has improper type for this operation. (Resetting)
Top-level loop ...
Controlling Pixie Scheme III:
(e::exit)
The Garbage Collectors:
Technical Note: This is not the place for
a technical discussion of garbage collection. There is a more detailed
description of Pixie Scheme III's garbage collectors in the "Glossary" section
of the Pixie Scheme III Dictionary,
which is available from within Pixie
Scheme III, via the "Help" menu. You might also look at
Jones and Lins [1996].
Suggestions for Using Pixie Scheme III:
Differences from R5 Scheme:
Run-Time Text Input:
(make-string)
(make-string)
make-string
R5 Section 1:
e::exit
R5 Section 2:
Technical Note: Pixie Scheme III lower-cases text strings used as
identifiers before looking up their bindings. To be more specific,
the Pixie Scheme III token scanner converts to lower-case all letters
except those used within character constants that represent single
letters, and except those used within string constants. (The rather
awkward wording about character constants is because, e.g., the Pixie
Scheme III token scanner is intended to allow #\newline, #\NEWLINE, and
#\Newline all to evaluate to the same character constant.)
'dEfiNE
define
`(a b ,@c)
(quasiquote (a b (unquote @c)))
(quasiquote (a b (unquote-splicing c)))
(e::permanent? 'define)
R5 Section 3:
R5 Section 4:
R5 Section 5:
Technical Note: That choice allowed a particularly simple means
of implementing internal definitions. I will add more error-checking
for defines in doubtful locations in future releases.
R5 Section 6:
<numerator>/<denominator>
-1/3
Technical Note: The rationale for not making the
implementation of rational numbers with numerator and denominator
stored separately more general -- and in particular, the rationale for
making such numbers "anticontagious" -- stems from the fact that
Pixie Scheme III's underlying representation of integers is 64-bit. When
performing scientific or engineering calculations, it is commonplace
that the numbers represented often rapidly leave the domain in which
fractions can be expressed using 64-bit signed integers. Therefore,
the "anticontagious" feature is useful to speed up such calculations
and to make the display of output more regular. Yet specific calculations
involving expressly represented fractions are still possible within the
range that 64-bit signed integers allow.
(define a 1.+1i) ;; ==> a
(define b 1+1.i) ;; ==> b
(eqv? a b) ;; ==> #t (in pure R5 Scheme).
(real-part a) ;; ==> 1. (an inexact number)
(real-part b) ;; ==> 1 (an exact number)
(define a 1.+1i) ;; ==> a
(define b 1+1.i) ;; ==> b
(eqv? a b) ;; ==> #f (in Pixie Scheme III).
(equal? a b) ;; ==> #f (in Pixie Scheme III).
=
<
>
<=
>=
max
min
positive?
negative?
=
<
>
<=
>=
max
min
report an error when asked to compare two
infinities of the same sign.
number?
complex?
real?
rational?
integer?
Technical Note: That was a design choice. Alternatively, I
might have arranged to report an error.
#e12##
12a3
#d12a3
#x12a3
4771
Internal Representations of Numbers:
Pixie Scheme III considers a number to be exact if, and only if,
its only possible value is a single point in the complex plane.
Thus:
returns #t if, and only if, both
(exact? z)
(exact? (real-part z))
and
(exact? (imag-part z))
also return #t.
(exact? z)
returns #f if, and only if, both
(exact? (real-part z))
and
(exact? (imag-part z))
also return #f.
Exactness -- "string->number" and "number->string":
#e1##
#e1##.
#e1.##e2
#e#xff##
100.
1e2
1.37e2
-100.
-1e2
-1.37e2
#e100.
#e1e2
#e1.37e2
-#e100.
-#e1e2
-#e1.37e2
#i100
10#
-#i100
-10#
100
-100
#i#b1110
#i#o16
#i#xe
-#i#b1110
-#i#o16
-#i#xe
#b1110
#o16
#xe
-#b1110
-#o16
-#xe
1e2
-1e2
9999999999999999999999999999999
#e1.e31
In Pixie Scheme III, the empty list counts as true in conditional expressions.
In Pixie Scheme III, the empty list is not equivalent (eqv?) to #f.
Pixie Scheme III does not provide "t" and "nil". (You can easily define them yourself.)
Pixie Scheme III provides two specialized "logic constants", "#u" and "#s", for use in logic programming. (See Friedman, Byrd and Kiselyov, 2005). Pixie Scheme III does not include any software based on this work; that's copyrighted, but you couldn't even get Pixie Scheme III to read these identifiers unless I built them in, because R5 identifiers are not generally allowed to start with '#'. So here they are, for anyone who wishes to use them.
Each of "#u" and "#s" evaluates to itself.
Pixie Scheme III provides a specialized non-printing object, "#n", whose printed representation is an empty string and which furthermore will cause Pixie Scheme III's top-level read-eval-print loop to omit printing a newline when #n is the result of the "eval" part of the loop. See the discussion here.
Pixie Scheme III has no uninterned symbols; in particular, those returned by "string->symbol" are already interned. Of course, not every symbol is necessarily associated with a value. Pixie Scheme III will report an error when it tries to evaluate such an unbound symbol.
The boolean procedures that compare characters all take precisely two arguments. Those procedures are:
char=? char-ci=? char<? char-ci<? char>? char-ci>? char<=? char-ci<=? char>=? char-ci>=?
Pixie Scheme III uses the ASCII ordering of characters, and does not accept non-ASCII characters for any purpose.
The procedure "integer->char" is capable of producing any ASCII character, even ones that the Pixie Scheme III interpreter does not accept as typed input. Pixie Scheme III displays some of these characters strangely.
Pixie Scheme III uses text names for two additional characters beyond the R5 Scheme standards of #\newline and #\space. The external representations of these characters are #\tab and #\return; they stand for the ASCII characters whose values as decimal integers are respectively 9 and 13. Pixie Scheme III's character-handling procedures handle them in a manner analogous to #\space and #\newline. Also see Slashification.
6.3.5:
When procedure "make-string" is called with no arguments, it prompts you to type the intended content of the string in the Pixie Scheme III dialog panel. Enclosing double-quotes are not necessary. The full list of standard Scheme procedures that use the dialog panel in this manner is given in the section on Run-Time Text Input.
The boolean procedures that compare strings all take precisely two arguments. Those procedures are:
string=? string-ci=? string<? string-ci<? string>? string-ci>? string<=? string-ci<=? string>=? string-ci>=?
Pixie Scheme III uses the ASCII ordering of characters, and does not accept non-ASCII characters for any purpose.
Pixie Scheme III allows the "backslash" character, '\', to serve as a slightly more general "escape" than is required by the R5 report: Section 6.3.5 of that report reads in part
A doublequote can be written inside a string only by escaping it with a backslash (\), as in
"The word \"recursion\" has many meanings."
A backslash can be written inside a string only by escaping it with another backslash. Scheme does not specify the effect of a backslash in a string when it is not followed by a doublequote or backslash.
Pixie Scheme III takes advantage of the freedom implicit in the last quoted sentence in the following way:
"abcdefg\ hijklmn"
results in a string which contains an ASCII newline character after the 'g'. On the other hand, an attempt to input
"abcdefg hijklmn"
-- without the '\' -- would result in an error message.
Also see #\tab and #\return.
Pixie Scheme III implements "dynamic-wind" along the lines of the implementation given by Rees (1992). That implementation involves modifying "call-with-current-continuation". The unmodified version of "call-with-current-continuation" is available as an enhancement, "e::original-cwcc".
The Pixie Scheme III procedures "e::reset" and "e::exit", which are enhancements described in the section "Top-Level Control", will leave a call of "dynamic-wind" without invoking the "after" procedure that was part of that call. So will the corresponding commands to the Pixie Scheme III interpreter, which are performed via buttons.
Pixie Scheme III recognizes only the exact integer 5 as a valid value of the "version" argument for "scheme-report-environment" and for "null-environment".
The null environment contains bindings for three symbols that are not defined in the R5 report; namely "c::begin", "c::if" and "c::lambda". These names follow the naming convention for specialized enhancements outlined in the "Enhancements" section herein.
There is a possible ambiguity in the meaning of "interaction environment". The R5 report describes it as "the environment in which the implementation would calculate expressions dynamically typed by the user"; the only circumstance in which a Pixie Scheme III user can type expressions for evaluation is when Pixie Scheme III is reading at the top-level loop. I therefore made the interaction environment be the same as the top-level loop environment. Thus, e.g., typing at top-level:
(define a 'top-level) ;; ==> a a ;; ==> top-level (let ((a 'local)) a) ;; ==> local
but
(let ((a 'local)) (eval 'a (interaction-environment)))
;; ==> top-level ;; Not "local"
Recall that Pixie Scheme III is not intended to have an interface to the underlying file system, since it is at least in part a development prototype for an iPad application; such applications have only limited access to the iPad file system.
Pixie Scheme III does not provide the following procedures:
call-with-input-file call-with-output-file with-input-from-file with-output-to-file open-input-file open-output-file close-input-port close-output-port
Since Pixie Scheme III does not open files, it cannot provide ports for use in any of the functions in this section that accept optional port arguments.
Since Pixie Scheme III does not open files, it cannot provide ports for use in any of the functions in this section that accept optional port arguments.
Pixie Scheme III "slashifies" the characters "newline", "return", and "tab", in the procedure "write", but not in the procedure "display": That is, "write" prints "newline" as "\n", "return" as "\r", and "tab" as "\t". "Display" prints these characters literally: A "newline" moves the printing to the start of the next line, and so on.
This treatment matches the escaping of those characters within string constants.
Pixie Scheme III does not provide the following procedures:
load transcript-on transcript-off
7.1.1:
Using the nomenclature and typographic conventions of the R5 discussion of Scheme's lexical structure, Pixie Scheme III reads the input "<ureal R> i" as if it were "+ <ureal R> i". Thus for example:
3i
+3iThat is, they are both valid external representations of the complex number whose real part is zero and whose imaginary part is three. Yet in contrast, note that
iand
+iare not equivalent: The latter is a pure complex number whose imaginary part is one; the former is the symbol "i", which has no default binding in R5 Scheme and so has no a priori connection to complex numbers.
(define anInf (/ 1 0)) ;; ==> aninf (define aNan (- (/ 1 0) (/ 1 0))) ;; ==> anan (make-rectangular 1 aninf) ;; ==> 1+infi (make-rectangular 0 aninf) ;; ==> infi (make-rectangular 1 anan) ;; ==> nan
Also:
#ei ;; ==> +i #ii ;; ==> 1.i #e1e1i ;; ==> 10i #i1e1i ;; ==> 10.i #e1e10 ;; ==> #e1.e10 ;; "Old Macdonald had a farm ..." #xaei ;; ==> 174i ;; What happened to 'o' and 'u'?
Et cetera ad nauseam.
42 / 137(with white space) or to write a complex number as
73 + 88 i(ditto), but Scheme will not recognize these forms as single numbers: The first will be read and parsed as a sequence of three Scheme objects; namely, the integer forty-two, the symbol "/", which is normally bound to the Scheme procedure for division, and the integer one hundred thirty-seven. The second will be read and parsed as four objects; namely, the integer seventy-three, the symbol "+", which is normally bound to the Scheme procedure for addition, the integer eighty-eight, and the symbol "i", which has no default binding. To obtain the intended meanings as single numbers, you must write
42/137and
73+88iwithout any embedded white space. It is of course also true and unremarkable that because of the embedded white space,
123 45 678does not parse the same way as
12345678-- the former is three numbers while the latter is one -- but this case is very obvious and familiar. The syntactically similar situations involving fractions and complex numbers with embedded white space are less commonly considered.
1+2/3iis to be read as
1+(2/3)iand not as
1+2/(3i)This quirk is particularly vexing when the denominators of the fractions are large, as in
1+137/123456789iwhich must be read as
1+(137/123456789)ieven though that is not the way many people would interpret it at a glance.
In the section-by-section discussions above, of how Pixie Scheme III differs from the R5 standard, I have listed the optional R5 features that Pixie Scheme III lacks. These features are "optional" in that the R5 report mentions them, perhaps with such language as "some implementations support ...". Here they are once again, all in one place, in summary:
This section describes Pixie Scheme III's non-standard features, procedures and syntax. Many are rather conventional: Most implementations of Scheme will have them in some form, but they are sufficiently dependent on the particular computer and operating system in use that the R5 report cannot specify them. Others deal with matters of controversy in the Scheme community. Possibly some version of them will be incorporated into the standard at a future date. Meanwhile, I have provided what seems best to me.
There are a moderate number of enhancements that are specific to the look and feel of the Apple iPad, or that allow you to access special features of the iPad itself. And finally, there are some enhancements that allow you to inspect or modify parts of Pixie Scheme III at a rather low level. Some of these may be useful in debugging programs, or in satisfying your curiosity about what's going on. Others are there because I needed them for some purpose related to developing Pixie Scheme III, or for some personal project using Pixie Scheme III.
Some of these enhancements are identified by naming conventions. In particular, Pixie Scheme III uses symbols which begin with the characters "e::" for enhancements that in my opinion will probably be of broad interest to users, and "c::" for more specialized enhancements that will probably be less generally useful.
By and large, enhancements whose names begin with "e::" will be reasonably well-documented and will have reasonable handling of errors. They should be no risker to use -- with "risk" in the sense of unexpected crashes and mysterious behaviors -- than standard Scheme procedures, special forms, and macros. Furthermore, these enhancements are more likely to continue to exist in the same form in future releases of Pixie Scheme III, or at the very least, I will make a big to-do in documentation if there are changes.
Enhancements whose names begin with "c::" will be less-well documented, riskier, and more likely to change in future releases. Most of the "c::" enhancements are provided for my own use in developing Pixie Scheme III, or are auxiliaries used by standard Scheme procedures or by "e::" enhancements. I have left them in the release and documented some of them.
You might remember the distinction this way:
e:: for enhancement, c:: for caution
A cynic might have said:
e:: for enhancement, c:: for catastrophe
Note that all of Pixie Scheme III's procedures and special forms are described in detail, with examples and discussion, in the Pixie Scheme III Dictionary, which accompanies Pixie Scheme III and may be reached via the Pixie Scheme III Help Panel.
The term "applicative programming" means different things to different people. As an enhancement, Pixie Scheme III has means to make it easy to do a pretty good job at one of the kinds of programming that is commonly called "applicative". Specifically, there is means provided to do programming that is for the most part referentially transparent.
Referential transparency encapsulates the condition that every time you do the same thing, you get the same result. In the context of programming, the idea is that every time you call the same procedure or special form, with the same arguments, you should get the same answer, and furthermore, the procedure should have no observable side effects.
For example, the arithmetic procedure "+" is referentially transparent: Every time you call
(+ 2 2)
you can reasonably expect to get back the same answer -- 4. On the other hand, consider the following procedure, "foo":
(define (foo n)
(let ((return-value a))
(set! a n)
return-value))
Procedure "foo" is not referentially transparent, because it depends on the initial value of "a" (and I have assumed that "a" will be defined before "foo" is executed). For example, suppose that a starts out as 3, and that you call
(foo 42)
twice in a row. The value returned from the first call will be 3, but the value returned from the second call will be a different value, 42.
It is easy to see that the problem with "foo" stems from the use of "set!": It changes state, and that is the difficulty. After the "set!", there is a value in Scheme main memory, that is not garbage, that is different from what it was before. That is an observable side-effect: Any procedure that uses that value to determine its own returned value will not be referentially transparent.
Before getting on with the details of what that means and how it works, I must point out that there are a few problems with this simple notion of referential transparency:
With all that said, the actual details of the enhancement are simple. There is just one new procedure:
(e::perform-applicative <thunk>)
This procedure performs <thunk> with Pixie Scheme III's ability to change state turned off, and returns whatever <thunk> did. Specifically, within the code represented by <thunk>, any attempt to use any of the following procedures and special forms will be interpreted as an error:
set! set-car! set-cdr! string-fill! string-set! vector-fill! vector-set! e::clear-permanent! e::set-list-print-depth! e::set-list-print-length! e::set-permanent! e::set-tag! e::set-vector-print-depth! e::set-vector-print-length!
If <thunk> should create a continuation which is subsequently returned to (as by "call-with-current-continuation"), then that continuation will inherit the applicative restrictions.
By way of illustration:
(e::perform-applicative (lambda () (+ 2 2))) ;; ==> 4
but
(define a 3) (e::perform-applicative (lambda () (set! a 42)))
produces the error message:
In built-in routine "set!":
Problem: Attempt to use a non-applicative procedure or special form during applicative programming.
Last lambda called (which may have returned) was recently named:
thunk
Recent names of non-tail-recursive stacked lambda expressions:
e::perform-applicative
(Resetting)
Top-level loop ...
Pixie Scheme III comes with a simple class system for creating objects with encapsulated data and procedures. That system is generally similar in intent and in operation to the class systems in C++, Java, and other programming languages: It facilitates object-oriented programming in a straightforward way. Notwithstanding, the Pixie Scheme III class system is somewhat more crudely implemented than either of those other class systems.
It is beyond the scope of this document to describe what class mechanisms are for, or what object-oriented programming is all about, or how to think in terms of object-oriented design. There are books on those subjects -- hundreds of them. If you are not familiar with these concepts, this section of the Pixie Scheme III help file won't help you much: You should probably forget about the Pixie Scheme III class system until you have learned more about classes in general. I will proceed on the assumption that you have some familiarity with other class systems and their uses.
The procedure which provides access to the Pixie Scheme III class system is
(e::make-simple-class <symbol which the class takes to be its name> <list of classes from which the new class inherits> <list of lists like (<symbol> <object>) for class variables> <list of lists like (<symbol> <object>) for instance variables> )
The first list of lists provides the names of the class variables and their default bindings. The second list of lists provides the names of the class's instance variables and their default bindings. The procedure returns a class in the Pixie Scheme III class system.
Many examples follow shortly.
As long as all of the names therein are distinct, the system will do just fine; that is, if there is only one instance variable named "frob" among all those names, Pixie Scheme III doesn't need to know which class it was inherited from in order to set it, get it, or apply it as a method.
Pixie Scheme III will warn you if a flattened namespace contains any duplicated names, but it will not prevent you from creating classes with such duplications. Just be sure you know what you are doing, if you do.
For example, you could start the names of variables in each class with the name of that class. Thus in a class named "foo", you might have variables "foo-x", "foo-y", and so on. That will work as long as a class has "foo" in at most one place in its inheritance.
You may of course create any specialized methods you wish to run after you have created an instance of a class, but you will have to run them yourself. One way to do that is to create a specialized procedure that creates the class instance, then runs your method, and then returns the modified class instance.
A Simple Class Example -- Right Triangles:
Let's go through a simple example. Suppose we want to have a class of right triangles. It takes two sides to define one -- say, side-1 and side-2. Here is the Pixie Scheme III code to create a minimal version of such a class. (You can cut and paste this code into Pixie Scheme III to try it out.)
(define right-triangle
(e::make-simple-class
'right-triangle
'()
'()
'((side-1 0) (side-2 0))
)
)
In that code, "e::make-simple-class" is the procedure to make a class, whose full syntax I have not yet described. The first argument, "'right-triangle", -- note the quote -- is what the class will understand its name to be. It will be used, for example, in constructing error messages, things like "While trying to create a class of type 'right-triangle', the world suddenly came to an end. Sorry about that." Note that in this example, that argument happens to be the same as the first argument to "define", here:
(define right-triangle ;; ... )
There is no requirement that those two symbols be the same, but it is good practice to make them so.
The second argument, which is '(), would be a list of classes that "right-triangle" inherited from, except there aren't any.
The third argument, which is also '(), would be a list of class variable names and default values, except that there aren't any yet. (Class variables are shared by all instances of the given class.)
The fourth argument is list of instance-variable names and default values that will be used by each instance of the given class. Again, note the quote. I hope the syntax is obvious, and you do have to provide a default value for each instance variable. There are other ways you could have built up this list. For example, instead of writing
'((side-1 0) (side-2 0)),
you might alternatively have written
(list (list 'side-1 0) (list 'side-2 0))
Now let's make a triangle:
(define first-triangle (right-triangle '()))
The argument to "right-triangle" is a list of overrides to the default instance-variable values, except there aren't any.
We now have created a right triangle whose sides are both zero. You get the instance-variable values like this. Note the quotes.
(first-triangle 'side-1) ;; ==> 0 (first-triangle 'side-2) ;; ==> 0
A triangle with zero-length sides is not very interesting. Let's fix that. Watch those quotes.
(first-triangle 'set! 'side-1 3) ;; ==> 0 (first-triangle 'set! 'side-2 4) ;; ==> 0 (first-triangle 'side-1) ;; ==> 3 (first-triangle 'side-2) ;; ==> 4
We could have made a triangle with non-zero side lengths by passing in a list of initializers when we made it:
(define first-triangle (right-triangle '((side-1 5)(side-2 12)))) (second-triangle 'side-1) ;; ==> 5 (second-triangle 'side-2) ;; ==> 12
One thing we might want to know about a right triangle is the length of its hypotenuse. Let us redefine the right-triangle class to include a class method that calculates the hypotenuse. For clarity, I will define the method first, then reconstruct the class and the instances.
(define (hypotenuse-code this)
(let
((a (this 'side-1))
(b (this 'side-2))
)
(sqrt (+ (* a a) (* b b)))))
What's this about "this"? Wait and see ...
In the new class definition immediately below, note the use of back-quote and comma in providing the binding for the class variable "hypotenuse". I could also have just used "list" explicitly, as in (list (list 'hypotenuse hypotenuse-code)).
(define right-triangle
(e::make-simple-class
'right-triangle
'()
`((hypotenuse ,hypotenuse-code))
'((side-1 0) (side-2 0))
)
)
(define first-triangle (right-triangle '()))
(first-triangle 'set! 'side-1 3) ;; ==> 0
(first-triangle 'set! 'side-2 4) ;; ==> 0
(define second-triangle (right-triangle '((side-1 5) (side-2 12))))
(first-triangle 'method 'hypotenuse) ;; ==> 5
(second-triangle 'method 'hypotenuse) ;; ==> 13
The point about "this" is that when you send a "method" message to a class instance, the method you name -- in this case "hypotenuse" -- is called with the class instance itself prepended to any other method arguments you may have provided. The effect in the two cases just given is as if "hypotenuse-code" were called as follows:
(hypotenuse-code first-triangle) (hypotenuse-code second-triangle)
Note that you do not have to use the name "this" for the corresponding name in the argument list of "hypotenuse-code". You can call that argument anything you like. Names like "this" or "self" are conventional, though.
Methods may have other arguments than "this". For example, you might have wanted a method for right triangles that returned a boolean value, #t or #f, depending on whether the hypotenuse of the triangle was greater than a passed value. The code for that method might be written like this:
(define (hypotenuse-greater-than-code this x) (> (this 'method 'hypotenuse) x))
Then you could have yet another redefinition of the right triangle class:
(define right-triangle-again
(e::make-simple-class
'right-triangle-again
'()
`((hypotenuse ,hypotenuse-code)
(hypotenuse> ,hypotenuse-greater-than-code)
)
'((side-1 0) (side-2 0))
)
)
(define first-triangle-again (right-triangle-again '()))
(first-triangle-again 'set! 'side-1 3) ;; ==> 0
(first-triangle-again 'set! 'side-2 4) ;; ==> 0
(define second-triangle-again (right-triangle-again '((side-1 5) (side-2 12))))
(first-triangle-again 'method 'hypotenuse) ;; ==> 5
(second-triangle-again 'method 'hypotenuse) ;; ==> 13
(first-triangle-again 'method 'hypotenuse> 8) ;; ==> #f
(second-triangle-again 'method 'hypotenuse> 8) ;; ==> #t
In the last two calls, the effect is as if "hypotenuse-greater-than-code" were called as follows:
(hypotenuse-greater-than-code first-triangle-again 8) (hypotenuse-greater-than-code second-triangle-again 8)
Let's see about inheritance. First let's define a simple class for colored objects:
(define colored-object
(e::make-simple-class
'colored-object
'()
'()
'((color chartreuse))
)
)
(define test-colored-object
(colored-object '((color vermilion))))
(test-colored-object 'color) ;; ==> vermilion
Now let's define a class for a colored right triangle
(define colored-right-triangle
(e::make-simple-class
'colored-right-triangle
(list right-triangle colored-object)
'()
'()
)
)
The new class inherits from "right-triangle" and from "colored-object", and does not add any more instance variables of its own. Let's make and test some colored triangles.
(define first-triangle (colored-right-triangle '()))
(first-triangle 'set! 'side-1 3) ;; ==> 0
(first-triangle 'set! 'side-2 4) ;; ==> 0
(first-triangle 'set! 'color 'burgundy)
(define second-triangle
(colored-right-triangle
'((side-1 5) (side-2 12) (color puce))))
(first-triangle 'method 'hypotenuse) ;; ==> 5
(first-triangle 'color) ;; ==> burgundy
(second-triangle 'method 'hypotenuse) ;; ==> 13
(second-triangle 'color) ;; ==> puce
If you would like to investigate some of the inner details of a class, there are a few extra variable names that all classes will have, and all class instances will respond to.
(first-triangle 'class-name) ;; ==> colored-right-triangle (first-triangle 'class-variable-names) ;; ==> (hypotenuse) (first-triangle 'all-variable-names) ;; ==> (side-1 side-2 color all-variable-names inheritance class-variable-names class-name this hypotenuse) (first-triangle 'inheritance) ;; ==> (colored-right-triangle (right-triangle) (colored-object))
That last says that "colored-right triangle" inherits both from "right-triangle" and all its ancestors (except there aren't any), and from "colored-object" and all its ancestors (except there aren't any of those, either).
(first-triangle 'this) ;; ==> #<Interpreted lambda expression, possibly named ">*<">
It would probably be a bad idea to "set!" "this". Don't say I didn't warn you.
Inheritance -- A Familiar Example:
Here is an example of multiple inheritance based on the genetic inheritance of a child from the two previous generations.
(define maternal-grandmother (e::make-simple-class 'maternal-grandmother '() '() '())) (define maternal-grandfather (e::make-simple-class 'maternal-grandfather '() '() '())) (define paternal-grandmother (e::make-simple-class 'paternal-grandmother '() '() '())) (define paternal-grandfather (e::make-simple-class 'paternal-grandfather '() '() '())) (define mother (e::make-simple-class 'mother `(,maternal-grandmother ,maternal-grandfather) '() '())) (define father (e::make-simple-class 'father `(,paternal-grandmother ,paternal-grandfather) '() '())) (define child (e::make-simple-class 'child `(,mother ,father) '() '())) (define a-child (child '())) (a-child 'inheritance) ;; ==> (child (mother (maternal-grandmother) (maternal-grandfather)) (father (paternal-grandmother) (paternal-grandfather))) ;; ;; ... or, reformatted for clarity ... ;; ;; ==> (child ;; (mother ;; (maternal-grandmother) ;; (maternal-grandfather) ;; ) ;; (father ;; (paternal-grandmother) ;; (paternal-grandfather) ;; ) ;; )
Class variables are shared by all instances of the given class. They are commonly used to hold methods associated with the class, but there are other possible uses. Perhaps you wish to implement a counter of some sort that is shared by all instances of a class, or maybe an inter-instance signaling mechanism. Here is an example that shows the use of a class variable as a counter.
(define (increment-counter-code this)
(this 'set! 'counter (+ (this 'counter) 1)))
(define class-variable-example
(e::make-simple-class
'class-variable-example
'()
`((counter 0)
(increment-counter ,increment-counter-code)
)
'()
)
)
(define instance-1 (class-variable-example '()))
(define instance-2 (class-variable-example '()))
(instance-1 'counter) ;; ==> 0
(instance-2 'counter) ;; ==> 0
(instance-1 'method 'increment-counter)
(instance-1 'counter) ;; ==> 1
(instance-2 'counter) ;; ==> 1
(instance-2 'method 'increment-counter)
(instance-1 'counter) ;; ==> 2
(instance-2 'counter) ;; ==> 2
As you see, the new value of the class variable is seen by both instances, no matter which instance has changed it.
Class variable values are only shared by instances of a particular class. There is no sharing of class variables between different classes, even if one inherits a class variable from another, or if both inherit the same class variable from a common ancestor.
For example, suppose that class "root" has a class variable named "root-var". Suppose that classes "branch-one" and "branch-two" both inherit from "root". Then all instances of "branch-one" will share one value of "root-var", all instances of "branch-two" will share another, independent value of "root-var", and all instances of "root" itself will share yet a third independent value of "root-var".
Methods and Procedures as Variables:
It is important to note that you may, if you wish, store a procedure which is not intended to be used as a method, as the value of a class variable or an instance variable. Recall that when you invoke a class instance with "'method", the value of the variable you name is treated as a procedure, and that the actual class instance in question is prepended to whatever other arguments you supply, for you to use as the value of "this" or of some other convenient variable name.
Alternatively, suppose we had a class whose sole purpose was to store functions to do trigonometric or geometric calculations. Such a class might very well store a hypotenuse procedure, which we could get out and apply to any two numbers that we considered to be the sides of a right triangle. That is not as contrived an example as it seems: Perhaps we are doing calculations in Euclidean and non-Euclidean geometries, and we want to see what the properties of shapes are in several such instances of geometries. Anyway, let's define a simple class:
(define (hypotenuse-procedure a b)
(sqrt (+ (* a a) (* b b))))
(define geometry
(e::make-simple-class
'geometry
'()
`((hypotenuse ,hypotenuse-procedure))
'()
)
)
(define my-geometry (geometry '()))
To use the hypotenuse procedure, we just pull out the value of the variable "'hypotenuse" and use it as a procedure.
((my-geometry 'hypotenuse) 8 15) ;; ==> 17
I hope you see the difference. The symbol "'method" appeared nowhere in the use of the "geometry" class. We are in effect just storing ordinary procedures, which do not need a "this" variable, as the values of variables of the class.
(e::make-simple-class <symbol which the class takes to be its name> <list of classes from which the new class inherits> <list of lists like (<symbol> <object>) for class variables> <list of lists like (<symbol> <object>) for instance variables> )
For example, to create a class with one instance variable, "a", and a class variable "add-to-a", which will be a method that will add a number to "a":
(define (add-to-a-code this n) (+ (this 'a) n))
(define foo-class
(e::make-simple-class
'foo
'()
`((add-to-a ,add-to-a-code))
'((a 0))
)
)
(define my-foo (foo-class '())) (define my-foo (foo-class '((a 42))))
class-name ;; Symbol naming the class.
class-variable-names ;; List of symbols which name
;; the class variables.
inheritance ;; A tree, in list form, showing
;; the (multiple) inheritance of
;; the given class.
all-variable-names ;; List of symbols which name
;; all the variables of the given
;; instance of the class -- both
;; class and instance variables.
this ;; The instance of the class.
(my-foo 'a) ;; Returns my-foo's value of a. (my-foo 'set! 'a 3) ;; Sets my-foo's value of a to 3. (my-foo 'method 'add-to-a 42) ;; Adds 42 to my-foo's value of a.
Pixie Scheme III contains a simple compiler: What it produces is not native code for the iPad microprocessor, but merely a somewhat more optimized form of Scheme, which the interpreter can evaluate more quickly.
Pixie Scheme III has an internal "compile defines" flag that causes each "define" automatically to compile the quantity being defined, provided that "define" is used with the syntax
(define (<name> <argument> ...) ... )
that is, with parentheses around the function name and argument list.
That flag is turned on and off by checking and unchecking the "compile defines" item of the Features Panel, or by using the procedures described in the Enhancements section under State Flags. With the flag on,
(define (inc x) (+ x 1))
will create a compiled procedure called "inc", that adds one to its argument.
The idea of compilation is to do as much of the work of a program as possible just once, at compile-time, instead of many times, every time the program is run. Thus the compiler ...
Precalculates the positions within the environment of variables (including the arguments) referenced by compiled procedures,
Inserts the actual values of variables that are "permanent", within the bodies of compiled procedures.
Code that has had these things done runs much faster than code that has not.
Even if the "compile defines" menu item is not checked, the compiler will expand macros in procedures that are "define"d using the syntax
(define (<name> <argument ...>) ... )
If the "compile defines" menu item is not checked, there is still a way to compile things, using the procedure "e::compile-form":
(e::compile-form <form>)
in which <form> evaluates to what you want to compile. "<Form>" will typically be either a lambda expression or a symbol to which a lambda expression is bound. You will probably wish to bind the value returned by "e::compile-form" to a symbol, for subsequent use. For example, you might first enter
(define inc (lambda ( x) (+ x 1)))
followed by
(define inc (e::compile-form inc))
The result would be a compiled procedure called "inc", that adds one to its argument.
The compiler attempts to do something sensible with every <form>, but compilation has no effect on <form>s which do not evaluate to lambda expressions: Thus for example
(e::compile-form '(1 2 3)) ;; ==> (1 2 3).
If you define a lambda expression with "compile defines" flag off, then turn it on, you can compile the expression easily, as shown here:
With "compile defines" off:
(define foo (lambda ...)).
Then, after turning "compile defines" on:
(define foo (e::compile-form foo))
The compiler includes some other procedures of interest:
(e::define-no-compile <symbol> <form>) (e::define-no-compile (<symbol> ... ) <form> ... )
"e::define-no-compile" acts as "define" does when the "compile defines" flag is unchecked: That is, even if "compile defines" is checked, and even if quantity being defined evaluates to a lambda expression, nevertheless "e::define-no-compile" will merely bind the evaluated quantity to the <symbol>, without compiling it. Use "e::define-no-compile" to make sure something never gets compiled.
"e::define-no-compile" recursively searches its second argument for macro "calls", and expands any that it finds, before binding the result to the <symbol>.
Effective use of the compiler requires understanding how it uses the "permanence" mechanism. To make a symbol permanent is to make a promise to the compiler, that whatever value is associated with the symbol at compile-time will continue to be associated with it at run-time. Thus the compiler can substitute the value for the symbol once and for all in compiled code, and save the time required to look up the symbol time after time, at run-time. The down side of permanence is that if you ever decide to make a permanent symbol un-permanent, and change its value, you will have to recompile all the procedures that use it, that were compiled while it had the first permanent value. Otherwise, those procedures will continue to use the old value.
The typical symbols you will probably wish to make permanent are the names of procedures, and there is a special procedure to help a bunch of compiled, permanent procedures all know that they are all permanent. That function is "e::substitute-new-permanent-symbols"; you use it on a procedure that has already been compiled, to let that procedure know about symbols that it contains, that have been made permanent after it was compiled:
(e::substitute-new-permanent-symbols <form>)
Note that you do not have to bind the result of "e::substitute-new-permanent-symbols" to anything; that procedure modifies its argument: It looks through the function body for symbols that have become permanent, and substitutes in their values.
Here is some boiler-plate for how to use the "permanence" mechanism effectively in compiled code. Suppose that the "compile defines" menu item is checked, and that you wish to compile three functions, "foo", "bar" and "baz", that call each other, or that call themselves recursively, or both. The idea is to define them all first, then make them all permanent, then apply "e::substitute-new-permanent-symbols" to all of them. You do all this with the "compile defines" flag set:
(define my-function-names '(foo bar baz)) (define (foo ...) ...) (define (bar ...) ...) (define (baz ...) ...) (map e::set-permanent! my-function-names) (map e::substitute-new-permanent-symbols my-function-names)
The debugging mechanism provided with Pixie Scheme III is very incomplete, though there is a hook for making it better. Pixie Scheme III's mechanism for handling recoverable errors -- the kind that eventually return control to top level --knows to look for a symbol called "e::debug". If that symbol is bound to a procedure, the error-handling message will call it with a single argument. Thus you may create a debugger merely by defining "e::debug", like this:
(define e::debug (lambda (x) ...))Pixie Scheme III will then call "e::debug" as part of its error handling, after the error message has been printed, instead of returning control to the top-level environment.
The argument to "e::debug" will be a non-empty list of all the environments in the lexical scope of the place where the error happened. The last member of that list will be the top-level environment: It will be a vector, each of whose elements is a list of symbols. Every symbol bound in the top-level environment will appear in exactly one vector element. If the list that is passed to "e::debug" has more members, its first member will be a list of the symbols bound in the lexical scope most local to the error, its second will be a list of the symbols bound in the next lexical scope outward, and so on till the top level. Only the last member will be a vector; all the others will be lists.
You may have your "e::debug" do whatever you like with this information. You might display the symbols. It will be hard to obtain their values, because the environment list passed to "e::debug" as an argument is not the one Pixie Scheme III searches automatically from within "e::debug", when looking for variable bindings. What's more, the environment list is not a very interesting data structure for debugging. Much more useful would be access to Pixie Scheme III's run-time stack (which is different from the central processor's "machine stack"). You can always show the contents of this stack, whether from the debugger or not, by calling the procedure "e::show-stack", but there is presently no reasonable way to learn what procedures are associated with specific items on the stack, or to investigate any particular stacked item in more detail.
Your "e::debug" probably ought to terminate with a call to "e::reset", so that Pixie Scheme III will return to top-level for further input after "e::debug" has run.
Be careful that "e::debug" is correct code. It is difficult to recover from errors in the debugger. Recursive errors are particularly nasty: The handling of an error in the debugger invokes another copy of the faulty debugger, which causes another error, and so on.
In addition to whatever the debugger may do, Pixie Scheme III handles non-fatal errors simply: It prints out some information about the error and what caused it, before invoking any debugger that may be present. If no debugger is present, Pixie Scheme III then returns control to the top-level loop. Different things might happen when a debugger is loaded -- depending on what the debugger is supposed to do.
The printed information will include the name of the last lambda expression entered before the error was encountered, whether or not that lambda expression had returned. It will also include the names of all lambda expressions whose activation records are stacked in Pixie Scheme III's internal stack; however, this list will not include the names of lambda expressions that were departed from by a tail-recursive call: Their activation records will by then no longer be stacked.
If you are wondering what I mean by the "name" of a lambda expression, wait for a few paragraphs.
By the way, fatal errors are handled differently, depending on what they are and when they occur: Usually, Pixie Scheme III will print out some kind of message and then exit. Any debugger present will not be called.
If the you ever see an with a message like
"Implementation error ..."
or
"Implementation: ..."
then I would very much appreciate a bug report with as many details as you can provide. (In particular, include the entire message.) Such messages indicate that I have inadequately guarded against some particular problem: It's my fault; I will be eager to do better.
The internal representation of a Pixie Scheme III lambda expression has a place where Pixie Scheme III can record an identifier, which I will somewhat incorrectly refer to as the lambda expression's name. This information can be of great use in a stack trace, for error reporting or debugging. That isn't quite as simple as storing the identifier to which the lambda expression is bound, because a lambda expression may be bound to more than one identifier, as in
(define (dessert-topping) (lambda () ...) ;; It's a dessert topping! (define floor-wax dessert-topping) ;; No! It's a floor wax!
Or a lambda may have no name at all, as in
((lambda (n) (+ n 1)) 3)
What Pixie Scheme III does is initialize each lambda expression's "internal" name to (). If a lambda is subsequently bound or assigned to a symbol, Pixie Scheme III records that symbol within the lambda expression, as its name. Thereafter, if that lambda expression should subsequently be rebound or reassigned by "define", by "set!", by "e::define-no-compile", Pixie Scheme III overwrites the old internal name with the new one. Those are the only ways to cause an internal name to be overwritten: Pixie Scheme III will not give a new internal name to a lambda which already has one, when that lambda is rebound or reassigned by any other means.
In particular, Pixie Scheme III will not set the internal name of a lambda expression to one of the top-level loop variables: I personally find that way too confusing when I am staring at debugger output.
Thus a lambda expression which has been named at top-level will not be renamed if it gets passed to a procedure as a parameter, or if it gets rebound locally by "let" or some similar mechanism. On the other hand, lambda expressions which do not have top-level names will be named at first opportunity, even if only by being bound to a local variable or to a formal parameter.
You might say that lambda expressions want names so badly that they will grab one at the first opportunity, and will give it up only when forced to do so.
I hope these conventions will correspond reasonably to your notions of what a lambda expression ought to think its name is, and that they will help with debugging in any case.
In case it is not yet clear, this business of storing a lambda expression's name inside the lambda expression is an addition to, not a substitute for or alteration of, the normal Scheme operations of binding and assignment: It is merely a debugging aid. If you didn't know about the "internal" names (and if you never made any mistakes that caused a stack trace to be printed), you'd never notice they were there. What's more, you don't need to know about them to use Pixie Scheme III.
Pixie Scheme III has an enhancement that allows creation and use of data structures that are set up automatically to be forgotten -- purged from Scheme main memory -- after some time has passed, even if they are not garbage in the formal sense of the word. The interface to forgettable objects lets you ask whether an object still exists before trying to use it, and provides you with knowledge and control of the precise details of when and if it disappears.
So what good is that?
As with most of the enhancements to Pixie Scheme III, I put this one in because I thought I might use it in personal projects. I am intending to provide a facility usable by artificial intelligence projects to mimic the "short-term memory" of biological minds. Stored data can go away, and instead of having a program crash when it tries to use an invalid reference, the interface provides a way to tell that "I forgot", which the program can then deal with, perhaps by rebuilding a data structure or by going out and making a new, current, observation of relevant real-world data. (That is sort of like what you and I do when we forget things, though perhaps without the whining.)
Note the difference in behavior from standard Lisp garbage collection of unreferenced items. With forgettable objects, a program can have what it thinks is a valid reference to something, and it won't find out that the reference no longer works till it tries to use it.
But wait, there's more! I tried to create a mechanism that would also allow several other useful behaviors related to forgetting things, such as:
A forgettable object is in essence a new kind of Scheme object, which is a wrapper around any Scheme object and two additional items:
Technical Note: Expiration times are "Unix times" -- unsigned integers which are interpreted as seconds since the beginning of calendar year 1970 (common era). In Apple Macintosh 64-bit applications, such as Pixie Scheme III, these integers are 64-bit, which means that Pixie Scheme III's mechanisms for dealing with time will cease to operate correctly approximately 6000000000000 years from now.
If you are still using Pixie Scheme III then, and you would like a better mechanism to deal with time, send me some EMail and I will see what I can do ...
Technical Note: Pixie Scheme III's particular implementation of forgettable objects actually involves three new kinds of Scheme objects: forgettable-unexpired, forgettable-forgotten, and forgettable-remembered.
Technical Note: If the forgettable object itself becomes garbage, then what happens to the Scheme object within it depends on whether that inside object is itself garbage. It may not be garbage in its own right; for example, it will not be garbage if you have defined at top level an object that is not an atom, bound it to an identifier, and then put that bound object into a forgettable object. The bound object will remain non-garbage as long as the top-level binding exists, without regard to the garbage status of the forgettable object into which it has been placed.
It does not make much sense to make atoms forgettable.
As an enhancement, Pixie Scheme III provides the procedure "e::atom?" to determine what kinds of objects are atoms. See the section about enhancements which are miscellaneous procedures.
Technical Note: At this stage, the garbage collector treats the pointer from the forgettable object to the things which it contains as a "weak reference", in the sense that the term is used elsewhere in computer science; for example, in Java, C#, Python, or Perl, or in Apple's Objective-C with garbage collection turned on. (Be cautious, the term "weak reference" means somewhat different things to different people.)
The garbage collector will then deal with unexpired forgettable objects that are not garbage themselves.
Technical Note: In effect, the the pointer from the forgettable object to the things which it contains is no longer a weak reference.
A forgettable object which is remembered is of course subject to normal garbage collection, if the forgettable object itself should become garbage. (Note once again, that just because the forgettable object is garbage does not necessarily mean that the object contained within it is also garbage.)
A forgettable object which is "forgotten" is of course subject to normal garbage collection, if the forgettable object itself should become garbage.
For example, a probability of remembering of 0.75 corresponds to a 75 percent chance of being remembered, and a 25 percent chance of being forgotten, once the forgettable object is past its expiration time and the object within it is otherwise garbage.
Programming Interface to Forgettable Objects:
(e::make-forgettable <given object> <a Unix time> <probability of remembering> )
Create and return an unexpired forgettable object containing the given object, with the given Unix time as its expiration time, and with the given probability of remembering.
(e::forgettable? <object>)
Is the given object a forgettable object?
(e::forgettable-forgotten? <object>)
Is the given object a forgettable object that has been forgotten?
(e::forgettable-remembered? <object>)
Is the given object a forgettable object that has been remembered?
(e::forgettable-unexpired? <object>)
Is the given object a forgettable object that is neither forgotten nor remembered?
(e::forgettable-object <forgettable-object>)
Returns multiple values: The first is #t if the forgettable object has not been forgotten and #f if it has been forgotten; the second is the stored object if the forgettable object has not been forgotten and is undefined if that object has been forgotten.
(e::forgettable-expiration-time <forgettable-object>)
Returns multiple values: The first is #t if the forgettable object has not been forgotten and #f if it has been forgotten; the second is the expiration time, which is still remembered by the forgettable object even if the object stored within it has itself been forgotten.
(e::forgettable-remember-probability <forgettable-object>)
Returns multiple values: The first is #t if the forgettable object has not been forgotten and #f if it has been forgotten; the second is the probability of remembering if the forgettable object has not been forgotten and is undefined if that object has been forgotten.
(e::set-forgettable-expiration-time! <forgettable-object> <a Unix time>)
Change the expiration time of the forgettable object to the new value provided. This operation will succeed if, and only if, the forgettable object is unexpired. Return #t if the operation was successful and return #f if not.
(e::set-forgettable-remember-probability! <forgettable-object> <probability>)
Change the probability of remembering of the given forgettable object to the new value provided. This operation will succeed if, and only if, the forgettable object is unexpired. Return #t if the operation was successful and return #f if not.
e::entropy-death
This symbol is bound to the largest value that Pixie Scheme III can store as a signed fixnum; if taken as a Unix time, it corresponds to approximately 3000000000000 years in the future.
Technical Note: It is presumptuous of me to label an epoch so near with a symbol that suggests that the Universe will have achieved entropy death by then. I beg forgiveness from inhabitants of solar systems whose suns are faint red dwarves.
Some Uses of Forgettable Objects:
Pixie Scheme III provides some support for logic programming in Scheme along the lines of Friedman, Byrd and Kiselyov, 2005). Pixie Scheme III does not include any of the fancy software from this work; that's copyrighted, but I hope there are enough primitives to get you going.
Each of "#u" and "#s" evaluates to itself.
(e::logic-constant? <object>)
Pixie Scheme III provides a specialized non-printing object, "#n", whose printed representation is an empty string and which furthermore will cause Pixie Scheme III's top-level read-eval-print loop to omit printing a newline when #n is the result of the "eval" part of the loop.
"#n" evaluates to itself. To see what "non-printing" means, compare the following examples, in which I have added comments to distinguish what you type at the keyboard from what Pixie Scheme III prints at the end of evaluation:
#t ;; You type #t, and then a newline.
#t ;; Pixie Scheme III evaluates #t as #t, which it prints, followed by a newline.
#n ;; You type #n, and then a newline, but Pixie Scheme III prints nothing.
;; In that last example, Pixie Scheme III actually evaluated #n to #n, but
;; that result was not displayed, nor was a newline.
(define x 3) ;; You type this definition, and then a newline.
x ;; Pixie Scheme III prints "x", and then a newline
x ;; You type "x", and then a newline.
3 ;; Pixie Scheme III prints its value, 3, and then a newline.
x ;; You type "x", and then a newline (again).
3 ;; Pixie Scheme III prints its value, 3, and then a newline.
(define y #n) ;; You type this definition, and then a newline.
y ;; Pixie Scheme III prints "y", and then a newline.
y ;; You type "y" and a newline, and Pixie Scheme III prints nothing.
y ;; You type "y" and a newline again, and Pixie Scheme III prints nothing.
I added "#n" primarily as a value to return from interrupt handlers. I had some interrupts that were called frequently but mostly did nothing; I wanted to have them print nothing at all so as not to clutter up log files with repetitive meaningless output. An interrupt handler has to return something to the top-level read-eval-print loop of the kitten which handles it, so a non-printing object was just the thing to use for a returned value.
Note that you can inspect the non-printing object and get a printable result. Thus in the previous example, the input:
(e::inspect y)
produces the output:
0000000000000025-0000000000000004: Peculiar Leaf -- Not a Car #<Non-printing object>
(e::non-printing-object? <object>)
You might consider the 'n' in "#n" to stand for "non-printing" or for "nothing".
This subsection describes some of the procedures and special forms that are present in Pixie Scheme III, that are not part of the R5 standard. I have by no means described all such extras: If you explore the system with the various low-level inspection tools described herein, you will find many procedures I do not mention. I am not trying to keep secrets: Rather, I have described only those enhancements that seem stable enough to use in your own code. The ones not described may change in detail or disappear entirely in future releases of Pixie Scheme III.
All the global symbols that I have used in constructing these enhancements start with either "e::" ('e' for enhancement) or with "c::" ('c' for compiler). To avoid naming conflicts with present and future enhancements, please do not create global symbols that start with either of these trios of characters.
And please be wary about using any "c::..." procedures in your own code. Some will cause a crash -- Pixie Scheme III will cease to operate -- if misused.
There are several procedures which allow direct manipulation of the individual bits of a 64-bit fixnum.
(e::bit-and <integer> <integer>)
(e::bit-not <integer>)
(e::bit-or <integer> <integer>)
(e::bit-xor <integer> <integer>)
Returns the bit-by-bit Boolean exclusive "or" of the arguments.
(e::bit-shift-left <integer> <integer>)
(e::bit-shift-right-arithmetic <integer> <integer>)
(e::bit-shift-right-logical <integer> <integer>)
See Long Ratnums and Continued Fractions.
(e::cons-with-continuation <object>)
This procedure is left over from older releases of Pixie Scheme III, that did not implement the "R5" Scheme standard. That standard has an "eval" procedure, which Pixie Scheme III now supports. Yet "e::cons-with-continuation" is still there, in case anyone wants to use it.
Many Lisps would call this procedure "eval". It causes its argument to be evaluated in the same environment as that in which "e::cons-with-continuation" itself was called.
Thus:
(e::cons-with-continuation '(+ 2 2)) ;; ==> 4 (define b 3) ;; ==> 3 (define a 'b) ;; ==> a (e::cons-with-continuation a) ;; ==> 3
What is going on in that last example is that when you type
(e::cons-with-continuation a) ;; ==> 3
the reader gets 'a, and the usual practice of evaluating the arguments to a procedure before calling it means that what is passed to "e::cons-with-continuation" is b. Procedure "e::cons-with-continuation" thus pushes b onto the next-to-be-evaluated end of the continuation, whereupon it is immediately evaluated to 3, which is what the top-level read-eval-print loop prints out.
The main use of "eval" and similar features is a bit more complicated, however: One typically builds up the argument to be passed to eval a piece at a time, often in quite distinct and changing environments, then evals it all at once:
(define to-be-evaled '()) (set! to-be-evaled (cons 'operator to-be-evaled)) (define x 42) (define y 88) (set-cdr! to-be-evaled (list 'x 'y)) (define x 2) (define y 2) (define operator +) to-be-evaled ;; ==> (operator x y) (e::cons-with-continuation to-be-evaled) ;; ==> 4
In contrast, suppose we had slightly changed the line containing "set-cdr!" ...
(define to-be-evaled '()) (set! to-be-evaled (cons 'operator to-be-evaled)) (define x 42) (define y 88) (set-cdr! to-be-evaled (list x y)) ;; NOTE: No quotes. (define x 2) (define y 2) (define operator +) to-be-evaled ;; ==> (operator 42 88) (e::cons-with-continuation to-be-evaled) ;; ==> 130
Here is another example: In it, note that even though "to-be-evaled" is defined in an environment in which x, y, and z are all zero, what happens when "to-be-evaled" is consed with the continuation depends on what x, y, and z were in the environment where that happened.
(define x 0)
(define y 0)
(define z 0)
;; At this point x, y and z are all zero.
(define to-be-evaled '(list x y z))
(let ((y 1)(z 1)) ;; Now y and z are one.
(let ((z 2)) ;; Now z is two.
(e::cons-with-continuation to-be-evaled)))
;; ==> (0 1 2)
In the past, there has been considerable controversy in the Scheme community concerning what "eval" ought to do, and whether it even ought to be part of the Scheme language at all. It took a long time for people to agree on the definition of "eval" used in R5 Scheme.
(e::error-port)
This procedure allows you to write your own error handlers that send messages to the same port that Pixie Scheme II uses.
(e::nan? <object>)
(e::inf? <object>)
(e::coerce-to-long-ratnum-if-possible <real>)
(e::coercible-to-fixnum? <object>)
(e::coercible-to-long-ratnum? <object>)
(e::continued-fraction-list->real <list of integers>)
(e::derationalize <real number>)
(e::long-ratnum? <object>)
(e::make-long-ratnum <integer> <integer>)
(e::real->continued-fraction-list <real>)
(e::inspect <object>)
Displays some useful information about the <object> and returns the <object>. Just what is displayed depends on what the <object> is. The fact that "e::inspect" returns its argument means that you can generally wrap a call to "e::inspect" around any expression in a Scheme program, to see what is going on, without otherwise interfering with the operation of the program.
In addition to the "hygienic" macro implementation described in the R5 report, Pixie Scheme III provides a "lower-level" macro implementation, that is more like the macro implementations in older forms of Lisp.
Besides, several key elements of Pixie Scheme III are written as Scheme macros using the older macro implementation.
(e::expand-macro <macro>)
(e::macro? <object>)
(e::macro <symbol> <expression>)
(e::macro-body <expression>)
(e::macro <symbol> <expression>)
is equivalent to
(define <symbol> (e::macro-body <expression>)
Pixie Scheme III implements this older form of macros in a rather conventional way. I will first describe this facility simply, glossing over some technical points, and will then fill in the details.
To begin, "e::macro" resembles "define": The action of
(e::macro <symbol> <expression>)
is to evaluate the <expression>, to declare that whatever the evaluation returns is a macro, and finally to bind that macro to the <symbol>.
The action of "e::macro-body" more nearly resembles the evaluation of a lambda expression: That is, the action of
(e::macro-body <expression>)
is merely to evaluate the <expression> and declare that whatever the evaluation returns is a macro.
There is one catch: The final action of the <expression> must be to evaluate a lambda expression of one argument, so that the procedure thereby created is the value that will become the macro. Pixie Scheme III reports an error if the value of the <expression> is not a procedure that was derived from a lambda expression of one argument.
A macro is invoked, or "called", by evaluating a pair whose car evaluates to a macro. That is, if you have defined
(e::macro my-macro ...)
then you may invoke my-macro as
(my-macro <stuff>)
The action of such a call is (1) to pass the entire pair -- in this case "(my-macro <stuff>)" -- to the procedure associated with the macro; whereupon (2) that procedure does whatever it is supposed to do, to the pair; and (3) the result returned by the procedure is itself evaluated.
Here is a simple example. Suppose you are tired of writing assignment statements in the form "(set! foo bar)", and would rather write them as "(assign bar to foo)" Define the macro:
(e::macro assign (lambda (form) `(set! ,(cadddr form) ,(cadr form))))
You can then write
(define foo #f) ;; ==> foo (define bar 3) ;; ==> bar (assign bar to foo) ;; ==> foo
The last expression assigns bar, which evaluates to 3, to foo. Now
foo ;; ==> 3
Let's look closely at how that works. The macro call "(assign 3 to foo)", causes the entire expression, "(assign 3 to foo)" to be passed as the argument "form" to "(lambda (form) `(set! ,(cadddr form) ,(cadr form))))". That procedure returns a list whose first element is "set!", whose second element is the cadddr of the form (namely the symbol "foo"), and whose third element is the cadr of the form, namely the number 3. That list, "(set! foo 3)" is in turn evaluated, causing 3 to become the value of foo.
You can see what is happening by evaluating
(e::expand-macro '(assign 3 to foo)) ;; ==> (set! foo 3)
This expression causes only the first two parts of the macro call "(assign 3 to foo)" to take place: It returns the unevaluated result from the procedure, namely the list "(set! foo 3)".
If you want to see the lambda expression itself, instead of what happens when you apply it, use "e::inspect". When you enter
(e::inspect assign)
Pixie Scheme III prints some information about where in Scheme memory the macro is located, then prints the lambda expression itself, though not as nicely pretty-printed as I have provided it here.
(lambda (form)
(quasiquote (set! (unquote (cadddr form))
(unquote (cadr form)))))
Note in passing that "assign" is not a very well-behaved macro. For simplicity, it does not include various tests for syntax errors. A better version would have a lambda expression that checked that "form" was a list of exactly four elements, that the third element was the symbol "to", and that the fourth element was a symbol.
The matter I have glossed over is what environments the various evaluations take place in. (Many people find the subject of environments confusing: You need not worry too much about this matter at first, though it may come back to haunt you if you become a serious Scheme enthusiast.)
Briefly, the expansion of a macro -- that is, the evaluation of the procedure of one argument that is assigned to the macro name -- takes place in the lexical scope of the macro definition; but the second evaluation, of whatever expression the expansion returns, takes place in the lexical scope of the macro call.
Here is an example that may make this issue clearer. Maybe ...
First, let's define a global variable, named "my-variable", whose value is the symbol "global-value".
(define my-variable 'global-value) ;; ==> my-variable my-variable ;; ==> global-value
Now let's create a macro named "foo", whose body contains several instances of the symbol "my-variable".
(e::macro foo
(display "Defining foo -- my-variable is ")
(display my-variable)
(newline)
(lambda ( the-argument-is-not-used )
(display "Expanding foo -- my-variable was ")
(display my-variable)
(display " in the environment where foo was defined.")
(newline)
(display "In the present environment my-variable is ")
'my-variable))
As "foo" is being defined, the first two "display"s and the subsequent "newline" are evaluated, so that what appears in the Pixie Scheme III window is
Defining foo - my-variable is global-value foo
The "display"s printed the value of "my-variable" in the environment where foo was defined; that value was still "global-value". The lambda expression was then converted into a procedure, which became the value of "foo", which was returned and displayed at top level. The procedure uses "my-variable" in the fifth-from-last line of its definition, in "display". The value of "my-variable" so referenced is again from the environment in which "foo" was defined. So when "foo" is called, it will print (reformatted here to make the lines shorter):
Expanding foo -- my-variable was global-value in the environment where foo was defined.
before the lambda expression returns any value.
The value returned by the lambda expression is a quoted symbol, "'my-variable", and that leading quote is a key to understanding what happens next. This expression will be evaluated in the environment in which the call to "foo" took place. In that environment, "my-variable" will not necessarily have the same value that it did in the environment where "foo" was defined. Thus after the return value has itself been evaluated, it will become
"In the present environment my-variable is <?>"
We don't now know for sure what the "<?>" will be.
To continue the example, let's create a local environment in which "my-variable" has as value the symbol "local-value", and call "foo" in that environment. We might evaluate
(let ((my-variable 'local-value)) (foo))
What gets printed is, after reformatting it to make the lines shorter:
Expanding foo -- my-variable was global-value in the environment where foo was defined. In the present environment my-variable is local-value
(e::all? <list>)
(e::any? <list>)
(e::atom? <object>)
(e::closed-port? <object>)
(e::fixnum? <object>)
(e::float? <object>)
These formats can represent integers, rationals which are not integers, IEEE nans and IEEE infinities. Pixie Scheme III finds occasion to use IEEE formats for all of these entities.
(e::forced? <object>)
(e::long-complex? <object>)
(e::promise? <object>)
(e::deep-copy <object>)
(e::error <string>)
(e::warning <string>)
(e::gensym)
(c::load-from-string <string>)
(e::make-integer-range <integer> <integer> <nonzero integer>)
(e::make-integer-range 0 10 1)
returns (0 1 2 3 4 5 6 7 8 9).
(e::original-cwcc <object>)
(e::read-string-with-prompt <string>)
(e::reduce <binary-operation> <list> [<start-value>])
(e::reduce + (list 2 3 4 5) 42)
calculates ((((42 + 2) + 3) + 4) + 5), which is 56.
(e::select <predicate> <list> [<key>])
(e::select positive? '(1 -1 0 2 -2 3 -3)) ;; ==> (1 2 3)
but
(e::select positive? '((a 1) (b -1) (c 0) (d 2) (e -2) (f 3) (g -3) ) cadr) ;; ==> ((a 1) (d 2) (f 3))
Thus for example, the list elements may be some sort of structure, and the <key> gives you the chance to pull out a particular part of the structure for testing by the <predicate>: In the case just shown, the structure is a list of two items, and the particular part is the second item.
You could always do the same thing by using a specialized lambda expression for the <predicate>, but sometimes using the <key> makes things clearer.
(e::select <predicate> <list> [<key>])
(e::select positive? '(1 -1 0 2 -2 3 -3)) ;; ==> (1 2 3)
but
(e::select positive? '((a 1) (b -1) (c 0) (d 2) (e -2) (f 3) (g -3) ) cadr) ;; ==> ((a 1) (d 2) (f 3))
Thus for example, the list elements may be some sort of structure, and the key gives you the chance to pull out a particular part of the structure for testing by the predicate: In the case just shown, the structure is a list of two items, and the particular part is the second item. You could always do the same thing by using a specialized lambda expression for the predicate, but sometimes using the key makes things clearer.
(e::usleep <integer>)
Only the part of Pixie Scheme III that reads, evaluates, and prints Scheme expressions is put to sleep by this command. Pixie Scheme III will respond to many user actions while sleeping; for example, changes in window size. Actions that would cause the processing of Scheme expressions will not take place until Pixie Scheme III has waked up, and may block other user actions until wake-up has taken place.
In principle, calling "e::usleep" with a sufficiently large argument could cause Pixie Scheme III to sleep for an objectionable length of time. If that happens, you might have to push the iPad "Home" button to force Pixie Scheme III to terminate.
There is a special hazard to using the "e::usleep" procedure on the iPad. Invoking that procedure with a sleep time that is too long may make the iPad's operating system think that Pixie Scheme III has become unresponsive because of a bug or some other problem with the application; in that case, the iPad operating system may terminate Pixie Scheme III without warning. I have used "e::usleep" on the iPad with sleep times as long as 3000000 microseconds -- three seconds -- with no problem, but your mileage may vary. I decided to leave the "e::usleep" procedure installed in Pixie Scheme III, instead of taking it out entirely, because sleeping for short amounts of time is often useful when controlling the speed of interactive Scheme programs.
(e::version)
Pixie Scheme III implements the procedures "values" and "call-with-values", as described in the "R5" report. The implementation features an additional kind of Scheme object, which I have unimaginatively labeled a "multiple values return". The intended use of these objects is to pass data between "values" and "call-with-values", but if you should happen to call "values" in some context other than providing input to "call-with-values", you might encounter one. Thus, for example, at top level:
(values 2 3 4) ;; ==> #<Multiple Values Return> List of values: (2 3 4)
Furthermore:
(e::multiple-values? <object>)
Straight R5 Scheme provides no convenient way to format numbers in varying ways without writing a lot of code on your own. Pixie Scheme III has a few enhancements to do some of the common formatting tasks, and perhaps to make it easier to create your own code to do more such tasks.
The interface is built on a single low-level procedure, which uses the numeric formatting capabilities of the underlying C++ implementation in which Pixie Scheme III is written. (I do not propose to tell you how to do numeric formatting in C in this document, since there are plenty of widely available sources that do a better job of that than I could. For example, try typing "man printf" in a Unix shell, such as the Macintosh "Terminal" application.)
The low-level procedure is:
(c::number->string-with-c-format <number> <string>)
in which "scratch" is a pointer to a buffer containing 256 characters. Following this C++ call, the content of "scratch" is again copied into a newly-allocated string in Pixie Scheme III's main memory, so there is no need to worry about saving "scratch" or overwriting it.
Note that "c::number->string-with-c-format" does no checking whatsoever of whether its "string" argument is appropriate for use as a C++ "format" string. Thus there is a noteworthy probability that ill-considered use of this procedure may cause Pixie Scheme III to crash. This procedure is perhaps best used as a primitive for procedures which are themselves well tested and debugged.
Thus for example:
There are two additional procedures which operate at slightly higher level:
(e::number->string-with-n-decimals <number> <number>)
For example:
(e::money->string <number>)
If only one value will ever be bound or assigned to a particular symbol, you can speed up the operation of both interpreted and compiled code by making that symbol "permanent". You can reverse the process later, if necessary; but if you do, be sure to recompile any compiled expressions that use the symbol: Otherwise, strange things may happen. It is possible -- though perhaps not useful -- to make permanent a symbol that already has different values bound to it in different scopes.
Pixie Scheme III will report an error if you attempt to bind or to assign a value to a permanent symbol.
Most of the symbols that denote the built-in primitive operations of Pixie Scheme III are permanent. These symbols include "+", "car", "if", "call-with-current-continuation" and so on.
(e::set-permanent! <symbol>)
(e::clear-permanent! <symbol>)
(e::permanent? <symbol>)
The folks at MIT's project MAC, who wrote the original "MACLisp" (a 1970's-vintage Lisp that ran on mainframe computers, not -- as you might suppose from the name alone -- a Lisp for the Macintosh) issued special error messages if you tried to alter the values of T and nil in that system. They were:
VERITAS AETERNA -- do not setq T! NIHIL EX NIHIL -- do not setq nil!
They had the right idea. (Welcome to the twilight zone -- a CalTech graduate -- me -- just said something complimentary about MIT.)
Perhaps you can figure out how I know about those error messages ...
Elsewhere herein I tell how, in the early stages of development of Pixie Scheme -- Pixie Scheme III's predecessor -- I accidentally managed to create nearly nine billion separate and operationally inequivalent kinds of truth and falsehood.
I have occasionally wondered whether Jeff Raskin deliberately spelled "Macintosh" the way he did in order to include a subtle reference to project MAC. Or maybe he just thought somebody was all wet and needed a raincoat.
Eight procedures deal with parameters that control how much of a complicated list or vector gets printed, and thereby incidentally prevent Pixie Scheme III from entering an infinite loop when asked to print a circular data structure. There are four such parameters, but their values are not directly available: You must use the functions to manipulate them. One parameter limits the number of elements of a list that will be printed. If this parameter is 3, then '(1 2 3 4 5) will print as
(1 2 3 ...)
The second parameter similarly limits the number of elements of a vector that will be printed.
The third parameter limits the depth of nested lists that will be printed. If that parameter is 3, then '(((((foo))))) will be printed as
(((...)))
The fourth parameter similarly limits the depth of nested vectors that will be printed.
(e::list-print-depth)
(e::list-print-length)
(e::vector-print-depth)
(e::vector-print-length)
(e::set-list-print-depth! <positive integer>)
(e::set-list-print-length! <positive integer>)
(e::set-vector-print-depth! <positive integer>)
(e::set-vector-print-length! <positive integer>)
Two procedures provide access to a quite good Unix random number implementation:
(e::random)
(e::srandom <integer>)
See the Unix documentation for details of "random" and "srandom".
Five procedures deal with sorting and merging. These provide similar functionality to that in Scheme SRFI 95, which is on line at http://srfi.schemers.org/srfi-95/srfi-95.html as I write these words. (SRFI means "Scheme Request For Implementation", and refers to a large body of code specifications which the Scheme community has decided would be useful if generally available.) I cannot implement the SRFI precisely because it depends on another SRFI which I have not implemented, but I chose to provide similar functionality.
The merge and sort procedures are stable when used with comparison predicates that return #f when applied to identical arguments.
See the source code file "SortMerge.s", which is provided as part of the open-source distribution of Wraith Scheme and Pixie Scheme III, for details of the origin and copyright of the source code for these functions. In essence, much of that code derives from the work of Aubrey Jaffer, and is in public domain.
(e::merge <list> <list> <comparison procedure> [<key>])
Without the optional <key>, merges in sorted order, two lists which have already been sorted using the <comparison procedure>. That procedure might descriptively be named "less?", and is presumed to accept two arguments and to return a boolean value indicating whether the first argument is "less" than the second. For example:
(e::merge (list 1 3 5) (list 2 4) <) ;;==> (1 2 3 4 5)
If the optional <key> is present, then the procedure for deciding which of two elements is less, during both the initial sorts of the separate lists and the merge itself, is that the <key> is first applied to the elements being compared, and then the <comparison procedure> is applied to the results thereby obtained. A common use of the <key> is if the elements being compared are some kind of structure, such as a list or vector, and the "less?" procedure is intended to apply to only one element of the structure. For example, if the lists are themselves composed of two-element lists, and the desired comparison is based on the second elements of those lists, then the <key> "cadr" could be used to extract the second elements for comparison. For example:
(e::merge (list '(a 1) '(b 3) '(c 5)) (list '(d 2) '(e 4)) < cadr) ;;==> ((a 1) (d 2) (b 3) (e 4) (c 5))
You could always do the same thing by using a specialized lambda expression for the <predicate>, but sometimes using the <key> makes things clearer.
(e::merge! <list> <list> <comparison procedure> [<key>])
(e::sort <list or vector> <comparison procedure> [<key>])
Without the optional <key>, uses the <comparison procedure> to decide how to sort. That procedure might descriptively be named "less?", and is presumed to accept two arguments and to return a boolean value indicating whether the first argument is "less" than the second. For example:
(e::sort (vector 2 3 1) <) ;;==> #(1 2 3)
If the optional <key> is present, then the procedure for deciding which of two elements is less is that the <key> is first applied to the elements being compared, and then the <comparison procedure> is applied to the results thereby obtained. A common use of the <key> is if the elements being compared are some kind of structure, such as a list or vector, and the "less?" procedure is intended to apply to only one element of the structure. For example, if the lists are themselves composed of two-element lists, and the desired comparison is based on the second elements of those lists, then the <key> "cadr" could be used to extract the second elements for comparison. For example:
(e::sort (list '(a 2) '(b 3) '(c 1)) < cadr) ;;==> ((c 1) (a 2) (b 3))
You could always do the same thing by using a specialized lambda expression for the <predicate>, but sometimes using the <key> makes things clearer.
(e::sort! <vector> <comparison procedure> [<key>])
(e::sorted? <list or vector> <comparison procedure> [<key>])
Without the optional <key>, uses the <comparison procedure> as the basis for deciding whether one element is less than another. That procedure might descriptively be named "less?", and is presumed to accept two arguments and to return a boolean value indicating whether the first argument is "less" than the second. For example:
(e::sorted? (vector 1 2 3) <) ;;==> #t
If the optional <key> is present, then the procedure for deciding which of two elements is less is that the <key> is first applied to the elements being compared, and then the <comparison procedure> is applied to the results thereby obtained. A common use of the <key> is if the elements being compared are some kind of structure, such as a list or vector, and the "less?" procedure is intended to apply to only one element of the structure. For example, if the lists are themselves composed of two-element lists, and the desired comparison is based on the second elements of those lists, then the <key> "cadr" could be used to extract the second elements for comparison. For example:
(e::sorted? (list (c 1) (a 2) (b 3)) ;;==> #t
You could always do the same thing by using a specialized lambda expression for the <predicate>, but sometimes using the <key> makes things clearer.
Several procedures allow Scheme programs to examine and modify the internal flags that control whether defines are compiled automatically, and whether the display routines for numbers use the full precision available.
(e::set-compiler-on!) (e::clear-compiler-on!) (e::compiler-on?)
(e::set-show-full-precision!) (e::clear-show-full-precision!) (e::show-full-precision?)
(e::active-room)
(e::active-store-size)
(e::aging-room)
(e::full-gc)
(e::ninety-percent-used?)
(e::room)
(e::show-room)
(e::store-size)
This section deals with procedures that allow examination or modification of some of the internal data structures used by Pixie Scheme III. Abuse of some of these functions will cause fatal errors, crashes and other disasters. Detailed description of these data structures is beyond the scope of this help file; however, experienced Lisp programmers will know what I am talking about.
(e::bound-instance? <symbol>)
(e::get-tag <object>)
(e::set-tag! <object> <integer>)
(e::show-active-memory)
Fair warning: This procedure can generate enormous amounts of output.
(e::show-aging-memory)
Fair warning: This procedure can generate enormous amounts of output.
(e::show-dynamic-environment-list)
(e::show-environment)
(e::show-environment-list)
(e::show-memory)
Fair warning: If you call this procedure when Pixie Scheme III is using a large main memory -- say a Gigabyte -- and if that memory is full, or nearly so, the procedure may well attempt to generate a hundred million lines of output.
(e::show-stack)
(e::stack-depth)
(e::write-continuation)
(e::write-stack)
Several procedures allow top-level control of the operation of the Pixie Scheme III application:
(e::exit)
(e::reset)
Stops whatever Pixie Scheme III is doing, and returns control to you. You can also invoke the "e::reset" procedure from the "Reset Scheme" button.
(c::down-in-flames!!!)
I created this procedure so that I could easily test Pixie Scheme III's mechanism for reporting fatal errors.
Pixie Scheme III provides some "sense lights" -- in effect, light bulbs at the bottom of the main window -- that are under user control. There are eight of them. They are normally invisible and will remain so unless Pixie Scheme III procedures are used to make them show up. When they are visible, they are lined up in a row near the lower left corner of the Pixie Scheme III Window, as shown in the next figure.
Pixie Scheme III's sense lights, glowing various colors.
The sense lights are numbered 0 through 7, from left to right. Each sense light may have one of eight illumination states, and those states are also numbered. In illumination state zero, the sense light is turned "off" -- it is visible, but resembles an unilluminated panel light, as in the leftmost light in the preceding figure. Illumination states 1 through 6 correspond respectively to the light being lit with the color red, orange, yellow, green, cyan, or magenta. In illumination state 7, the light is emitting darkness -- it looks like it is glowing black.
The visibility of each sense light has nothing to do with its illumination state. If you make a visible sense light invisible, it retains whatever illumination state it previously had, and will reappear looking just the same after if you should make it visible again. Similarly, if you change the illumination state of a sense light that is invisible, the sense light does not show up -- it won't do that till you make it visible, but when it does it will have whatever illumination state you have just provided.
I did not create names for the separate colors or illumination states; that is, there is no built-in Pixie Scheme III object named "e::red" or anything like that. Feel free to define such auxiliaries if you wish.
Procedures for working with sense lights include:
(e::hide-sense-lights!)
(e::rotate-sense-lights! <integer>)
(e::sense-light-number? <object>)
(e::sense-light-illumination-number? <object>)
(e::set-sense-light-illuminations! <sense-light-illumination-state-number>)
(e::set-sense-light-n-illumination! <sense-light-number> <sense-light-illumination-state-number>)
(e::set-sense-light-n-visibility! <sense-light-number> <boolean>)
(e::set-sense-lights-off!)
(e::show-sense-lights!)
There is no way to read the illumination state or visibility of sense lights from Pixie Scheme III.
Note that "e::set-sense-light-n-illumination!" and "e::set-sense-light-n-visibility!" provide full control of sense light operation. The other procedures that affect illumination and visibility are for convenience.
Procedures which change the illumination state or visibility of sense lights are relatively slow to execute. When speed is particularly important, make minimal use of sense lights.
Like Common Lisp, Pixie Scheme III maintains several variables that may prove handy should you forget to save an interesting input expression or output result. Their names are closely related to the names of similar variables used in Common Lisp.
Common Lisp Pixie Scheme III
=========== =============
- >-<
+ >+<
++ >++<
+++ >+++<
* >*<
** >**<
*** >***<
Pixie Scheme III cannot use the exact same variable names as Common Lisp, because there is only one namespace in Scheme, and the symbols "+", "-" and "*" are already bound to the procedures for addition, subtraction and multiplication.
When Pixie Scheme III starts running, these variables are all initialized to the empty list.
>+< >++< >+++<
>-<
>*< >**< >***<
I am sure Pixie Scheme III contains bugs, and I want to hear about them so that I can fix them.
I am particularly worried about the possibility of bugs that are platform dependent, in that they occur on some combinations of iPad hardware and operating system and not on others. I do not have a large collection of different iPads to test Pixie Scheme III on, so it is logically conceivable that I might release a version of Pixie Scheme III containing a bug that I am not equipped to discover.
So by all means, do send in bug reports.
My EMail address is Jay_Reynolds_Freeman@mac.com.
If you cannot reach me by EMail, try paper mail to
If you ever encounter a fatal or non-fatal error with a message like
"Implementation error ..."
or
"Implementation: ..."
then I would much appreciate a bug report with as many details as you can provide. (In particular, include the entire message.) Such errors indicate that I have inadequately guarded against some anticipatable problem: It's my fault; I will be eager to do better.
The only reason I will release a distribution of Pixie Scheme III containing a known bug or a glaring flaw is that there is some reason I cannot fix the problem. At present I have none to report.
Read and Print Overflow:
Although Pixie Scheme III can store large and complicated data structures in its main memory, it cannot necessarily read them in all at once: Pixie Scheme III can read lists that are very long. In testing, I have loaded files whose text included lists of 100 000 items, something like:
'(item-1 item-2 ... item-99999 item-100000)
However, lists that are too deeply nested will cause Pixie Scheme III to crash. Such a list might be
'((( ... ((( some-list-item ))) ... )))
in which the "..." stands for tens of thousands of parentheses of the appropriate kind
There is a similar problem in the routines that print long or deeply-nested lists, but I have not tested to determine its extent.
Numerical Exactness:
Pixie Scheme III relies in part upon built-in features of iOS and of iPad hardware to determine whether or not the result of a floating-point arithmetic calculation is exact; this term refers among other things to what the standard Scheme procedures "exact?" and "inexact?" return. These built-in features may vary in capability from one version of iOS to the next, and from one kind of iPad hardware to another.
The main consequence here is that sometimes you might expect that a floating-point calculation would return an exact result, but the procedure "exact?" doesn't say that it did. Furthermore, what "exact?" has to say about the result of any given calculation may vary depending on what kind of hardware and which version of iOS you are running.
This mildly inconsistent behavior is not technically a Pixie Scheme III bug, since the R5 standard is rather lenient about requiring Scheme implementations to return exact results whenever possible, but it bugs me, so I thought I would report it here.
Numerical Accuracy:
The floating-point algorithms used by the iPad may differ from one version of iOS to the next and also from one kind of processor hardware to the next. Thus the numerical results returned by Pixie Scheme III floating-point calculations may vary depending on which version of iOS you are running and on what kind of hardware you have, even if you perform the same calculation, using the same input data. The differences are typically very small -- down in the least significant digits of the result -- but they are there. The trigonometric and inverse-trigonometric routines are where I have most often noticed such differences.
Here are a few hints about problems that may happen when you try to run Pixie Scheme III:
If Pixie Scheme III fails to open, it may be that the app itself has somehow become damaged, or it may be that you have previously saved a world for Pixie Scheme III, by pressing the "Save World" button in the Features Panel, and that the world has somehow become damaged. Try restoring Pixie Scheme III to original settings. That will delete the saved world and reinstall the application from your computer. Failing all else, contact me, Jay_Reynolds_Freeman@mac.com, for support.
It is of course possible that you are running a Scheme program that simply takes a long time to do its job, but there is at least one other possible cause of sloth that you might want to know about. The computer chip that runs Pixie Scheme III must also update the Pixie Scheme III window for you to look at, and the more text there is in that window -- including any text that has scrolled off screen -- the longer it takes. If there is any text in the window, or scrolled off the top or bottom, that you no longer need, it may help to delete it: Just select the text and then use the "Cut" command to remove what you have selected.
See the Scheme References and Lisp References sections. In order from simplest to most complicated, I recommend (1) Friedman and Felleisen, (2) Springer and Friedman, and (3) Abelson, Sussman and Sussman. And do get a copy of the "R5" report: You will need it sooner or later.
Or, try an Internet search.
Don't forget the help files available via the Help Panel.
Look in the Features Panel for commands to change font size. And hey, I like the yellow background.
Pixie Scheme III's internal compiler is indeed fairly slow, and I have no present fix for that problem. Remember that you can turn the compiler off, via the "Compile Defines" menu item in the Features Panel, or by means of procedures described in the State Flags section. Also, be advised that the compiler is much happier dealing with a large number of small procedures than with a small number of large ones.
Welcome to the club. Many programming editors have parenthesis-matching features; if you are developing code on a Macintosh, to run later on an iPad, you might try the version of Emacs that comes with Apple's "Xcode" development environment -- it runs in a Terminal shell. As I write these words, Xcode is available free from Apple.
I do not presently know of any editors that run on the iPad, that provide any assistance with balancing parentheses, except for the rather minimal support that Pixie Scheme III itself provides via the simple editor built into its main window.
Pixie Scheme III itself will also provide cues about missing parentheses and missing double-quotes when you try to evaluate expressions that are unbalanced in that respect.
If you encounter a problem while running Pixie Scheme III, you might want to do a few things on your own before contacting me, both to save your time if the problem turns out not to be Pixie Scheme III's fault, and to help me identify and fix any bug that may be present.
Try to pin down what it takes to make the problem happen, as accurately and completely as you can. Unreproducible bugs are almost impossible to fix. They are like the rattle in your car that goes away when you take it to a mechanic, or the things that go bump in the night but are not there when the sun rises.
Here are some things to do, that might help pin down a problem:
If the problem happened when you were running code that you had compiled, try again without compiling the code. That is, turn off the "Compile Defines" option, reload your code without applying "e::compile-form" to any of it, and try again. If the problem does not recur, or recurs in a different way, it may be that the difficulty is with the compiler itself.
Turn off your iPad and start it up again.
Try restoring Pixie Scheme III to original settings.
Carefully consider the possibility of a computer virus or similar software abomination. There are no general rules to detect these: No two are alike. Magazine articles, Internet searches, user groups and dealers can help you learn about the latest viruses. As I write these words, there are few viruses or other software threats to the iPad, and I hope that remains the case, but by all means, seek out the latest information on the matter.
See if you can duplicate the problem on another iPad. If so, then you will know that your own iPad's hardware and software are not at fault.
If you do send me a bug report, give your best description of the problem and of what I must do to make it recur for investigation. State what kind of iPad you used, how much memory it had, what version of iOS you used, and whether you were using the Pixie Scheme III compiler. If you suspect a problem with Pixie Scheme III's interaction with some other software, tell me about that, too.
It will help me a lot if you do these things and describe what happened, and you may be able to save yourself some time if the problem turns out to be one you can fix.
This section summarizes what is new in Pixie Scheme III since the previous release. I omit cosmetic improvements, minor changes in documentation, and minor changes in displays.
Items are listed in more or less the order in which I dealt with them.
The current release is 1.12, the fifth release of Pixie Scheme III.
This section summarizes changes in Pixie Scheme III between its first release and the last one before what is now current. I may not bother to mention minor bug fixes, cosmetic improvements, minor changes in documentation, and minor changes in displays.
Release 1.11 was the fourth release of Pixie Scheme III.
Version 1.10 was the third release of Pixie Scheme III.
Version 1.01 was the second release of Pixie Scheme III.
Version 1.00 was the first release of Pixie Scheme III, so everything was new.
Besides fixing bugs and making internal improvements, my wish list for the future of Pixie Scheme III includes the following items, which are not necessarily in the order in which I might get around to doing them:
The future probably does not hold:
R6 is a much more complicated standard than R5. I find most of its new features neither interesting nor useful to me personally, and there are other aspects of Scheme that I would prefer to work on. In that context, I simply don't have time enough to develop and maintain an R6 implementation of the quality that I would like to present as an iPad application.
There was a great deal of controversy about the R6 standard in the Scheme community. I hope no one will misconstrue lack of R6 support in Pixie Scheme III for me taking a position against the R6 standard and being too cowardly to say so. The plain truth is that I find the R6 standard overwhelming: It is too complicated for me to support all by myself.
Many people think the different kinds of numbers are separate, so that no number can be of more than one kind. They think that integers and reals are different kinds of numbers, so that no integer can be real, and so on.
That's false. They overlap. Specifically, every integer is also rational, real and complex; every rational is real and complex; every real is complex; and they're all numbers.
For example, 1 is an integer. It is also a rational (being equal to the quotient of two integers, namely 1/1, or 2/2, or...), it is on the real line, and it is also in the complex plane -- we could write it as 1 + 0i. Typographic choices, such as the inclusion of a decimal point, an exponent, or trailing zeros, do not alter the mathematics. Thus "1", "1.", "1.0", "1.0e0" and "1.000000000000000" are all ways to write the same mathematical number; namely, the integer "one".
Some wag once said, "A computer scientist is a person who refuses to believe that 1.0 is an integer." Don't you make that mistake.
Much of this confusion is because many computer languages use different kinds of machine storage for numbers given with a decimal point than for numbers given without one. A language might store "1.0" as an IEEE 64-bit floating-point number, yet store "1" as a 32-bit word with just the least-significant bit turned on. It is the integer "one" in either case. Some people think floating-point numbers cannot be integers. That's wrong. What counts is the value, not how it's stored.
If you want to know how Pixie Scheme III is storing a particular number, there are some special predicates you can use to find out.
More confusion stems from the fact that typographic conventions are widely used to convey information about the precision of a number when that number is imperfectly known. Thus in science or engineering, use of the string "1.000" to represent a number often means "the number I am talking about is between 0.9995 and 1.0005, but I don't know for sure what it is, so I will use the representative exact value 1 to stand in its place, and will give the value to four significant digits to hint at the level of my ignorance." This convention obscures the mathematics of numeric types: Thus in the example given, the integer 1 might actually be standing for the integer 1, for the rational number 10001/10000, for the irrational number (1 + pi/10000), or for the complex number (1 + i * pi/10000).
The built-in features of Scheme are in any case not powerful enough to support such conventions: You can specify that a number is exact or inexact by means of the "#e" and "#i" prefixes, but Scheme records only that one bit of information. There is no built-in means to tell Scheme how many digits of precision the number has. As far as input to Scheme is concerned, the strings "1.50000" and "1.5" indicate the same number and the same status of the "exact bit". (In the case of Pixie Scheme III, that number is the inexact rational 1.5.)
Just for fun, ask yourself (A) Which of the following numbers are complex? (B) Which are real? (C) Rational? (D) Integer?
42 1. -2.000000 345.62e2 9.6149604775e23
Answers: (A) All of them. (B) All of them. (C) All of them. (D) All of them.
These items are all from my bookshelves or download directories. Many have more recent editions.
These items are all from my bookshelves. Many have more recent editions.
Letter sent in 1988 to the editors of "The California Tech", California Institute of Technology, Pasadena, California:
Dear Editors:
This June it will be twenty years since I graduated from CalTech. The anniversary has made me think: Possibly my thoughts may be relevant to the present student body.
After CalTech I went to graduate school at the University of California's Berkeley campus. It was like going from a monastery to a madhouse. From the late sixties through the mid seventies, Berkeley was a tumultuous place, full of people who were bound and determined to change the world. What's more, each of them seemed to have a different idea of how to go about it. I could scarcely pass through the campus gates without being accosted by handbill-distributors from every imaginable kind of political, social and economic action group, all bent on modifying civilization to suit themselves. There were libertarians and communists, republicans and democrats, churches both bizarre and familiar, ecological advocates, draft resisters and military recruiters. The campus seemed overflowing with charismatic, impressive leaders, each with a separate agenda for social change.
Often there were demonstrations: I rapidly learned to cut through the back alleys to get to class. Sometimes there was real violence: Once I walked out of the student cafeteria after lunch, only to find a National Guard helicopter spraying the plaza with riot-control gas. I decided I had better go back inside and have dessert.
I was too bewildered to have anything to do with all this. I gravitated toward a small, ever-changing circle of science buffs and technology enthusiasts, people much like myself. We had no charisma and impressed no one. We would go out for pizza and talk. The discussion topics changed as our informal membership varied -- many liked space exploration, one was enthusiastic about computers, and so forth. If pressed, most of us would cautiously admit to some faith that scientific and technical developments were also important agents of social change, but in the midst of widespread turmoil of a different kind, I found such a belief ever less tenable. As the years passed, it seemed increasingly that the things I was interested in could scarcely matter in comparison to those other, more powerful forces.
Yet in retrospect, it is remarkable how little came from the social and political movements of that time and place. I no longer remember the names of any of the Berkeley people who were out to change the world. I scarcely recall what they wanted to do. After a decade or two I must look hard to find our planet any different for their efforts. It seems that in the long run, they mattered all but naught.
To my embarrassment, I have even forgotten most of the people in our group of pizza-eaters. Only recently did someone remind me of the name of the fellow who came to a few meetings and talked with such zeal about the prospect of small computers and their likely capabilities.
His name was Steve Wozniak.
Keep the faith.
Jay Reynolds Freeman
BS (Physics) '68
May 1, 1988
The following excuses may help explain flaws or omissions in Pixie Scheme III:
I do not possess your level of wisdom, insight or experience.
I didn't think of that.
I was interested in writing a Lisp system, not a (choose one or more)
text editor.
graphics interface.
NS/UI object interface.
whizzy graphics package.
...
I didn't know how.
I thought I knew how, but I was wrong.
I was too lazy to do it right.
I did it the the way the R5 report says it should be done.
I did it my way.
(Pretty much in alphabetical order, except for the cats, who of course have the last word.)
Apple Incorporated, for providing excellent software development environments and numerous examples of code, all for free.
The members of the Silicon Valley "Cocoaheads" group, for advice about the Pixie Scheme III user interface.
The creators of the various "Rn" Scheme reports, for providing much clear explanatory text and numerous examples -- both simple and subtle -- of how the language is supposed to work. I am particularly grateful for the example implementations of derived expression types in section 7.3 of the R5 report, which formed the basis of the implementation of most of those types in Pixie Scheme III.
Several users of earlier versions of Pixie Scheme III, and other members of the on-line Lisp and Scheme communities, for suggestions, advice, and sympathy.
Mike Deering, for lengthy discussions of tagged-pointer Lisps.
Libby Hudson, for moral and immoral support.
Sandy Lerner, for encouragement in development and advice on commercial prospects.
Tim May, for humor, and for the chance to play with his computer, software and other toys.
Charles Smith, for hiring me into a major artificial-intelligence laboratory.
Pixie, Wraith, and numerous other cats, for love and purrs, and for the sharing of their ineffable names.
Notwithstanding the honest acknowledgments and grateful thanks given above, I am confident that all errors and misfeatures in Pixie Scheme III are nobody's fault but mine.
-- Jay Reynolds Freeman, May 2011